
算法导论-实验报告
注:力扣题使用TypeScript进行解答,实验五使用c++,python,java三种语言实现。
实验一:问题转换(Leetcode #1、#287)
#1 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
题目解析:
暴力枚举法
-
通过双重循环,遍历到每一个元素,判断两数之和是否为需要的结果
/** * 暴力解法 */ function twoSum1(nums: number[], target: number): number[] { for (let i = 0; i < nums.length; i++) { for (let j = i + 1; j < nums.length; j++) { if (nums[i] + nums[j] === target) { return [i, j]; } } } throw new Error("No two sum solution"); }时间复杂度:
时间复杂度是 (O(n^2)),因为代码中有两个嵌套的循环。对于数组中的每一个元素 (i),都需要遍历其后的每一个元素 (j)。如果数组的长度为 (n),则外层循环执行 (n) 次,内层循环平均执行 (\frac{n}{2}) 次。所以总体时间复杂度是 (O(n^2))。
空间复杂度:
空间复杂度是 (O(1)),因为在这个算法中,我们只使用了有限的额外空间(即两个变量
i和j以及用于存储结果的数组number[])。这个额外空间的使用量与输入数组的大小无关,是常量级的,因此空间复杂度为 (O(1))。
哈希表解法
-
遍历一次数组,在map表中存储已经经过遍历的元素,在每一个元素的开始,判断能够组成目标数,需要什么数,然后去map中获取,若不存在则说明无法组成结果,若存在就可以返回了。
function twoSum(nums: number[], target: number): number[] { const map = new Map<number, number>(); for (let i = 0; i < nums.length; i++) { // 要查找的值是否在 map 中 const value = target - nums[i]; if (map.has(value)) { return [map.get(value)!, i]; } // 将当前值存入 map map.set(nums[i], i); } throw new Error("No two sum solution"); }时间复杂度:
时间复杂度是 (O(n)),因为我们只需要遍历数组一次。在每次遍历中,对哈希表的插入和查找操作都是 (O(1)) 的平均时间复杂度。因此,总体时间复杂度为 (O(n))。
空间复杂度:
空间复杂度是 (O(n)),因为我们使用了一个哈希表来存储数组中每个元素及其对应的索引。在最坏的情况下(当没有两个数的和等于目标值),我们需要在哈希表中存储所有的 (n) 个元素,因此空间复杂度为 (O(n))。
#287 寻找重复数
给定一个包含 n + 1 个整数的数组 nums ,其数字都在 [1, n] 范围内(包括 1 和 n),可知至少存在一个重复的整数。
假设 nums 只有 一个重复的整数 ,返回 这个重复的数 。
你设计的解决方案必须 不修改 数组 nums 且只用常量级 O(1) 的额外空间。
示例 1:
输入:nums = [1,3,4,2,2]
输出:2
示例 2:
输入:nums = [3,1,3,4,2]
输出:3
示例 3 :
输入:nums = [3,3,3,3,3]
输出:3
提示:
1 <= n <= 105nums.length == n + 11 <= nums[i] <= nnums中 只有一个整数 出现 两次或多次 ,其余整数均只出现 一次
题目解析:
1. 使用哈希表解法
通过一次遍历数组,在 map 中存储已经遍历的元素,如果发现当前元素已经在 map 中,则返回这个重复的元素。
function findDuplicate1(nums: number[]): number {
const map = new Map<number, number>();
for (const num of nums) {
if (map.has(num)) {
return num;
}
map.set(num, num);
}
return -1;
}
时间复杂度: (O(n))
空间复杂度: (O(n))
2. 快慢指针解法
利用快慢指针(Floyd 判圈算法)找到重复数字。快慢指针第一次相遇时,找到环的入口点,这个入口点即为重复数字。
function findDuplicate2(nums: number[]): number {
let slow = 0;
let fast = 0;
do {
slow = nums[slow];
fast = nums[nums[fast]];
} while (slow !== fast);
let ptr1 = 0;
let ptr2 = slow;
while (ptr1 !== ptr2) {
ptr1 = nums[ptr1];
ptr2 = nums[ptr2];
}
return ptr1;
}
时间复杂度: (O(n))
空间复杂度: (O(1))
3. 二分查找解法
通过二分查找确定重复数字。利用数组中元素的值的分布特点,根据中间值 mid 计算不大于 mid 的元素数量,调整搜索区间。
function findDuplicate3(nums: number[]): number {
let left = 1;
let right = nums.length - 1;
while (left < right) {
const mid = left + Math.floor((right - left) / 2);
let count = 0;
for (const num of nums) {
if (num <= mid) {
count++;
}
}
if (count > mid) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}
时间复杂度: (O(n \log n))
空间复杂度: (O(1))
4. 原地修改解法
将元素标记为负数,如果发现元素已经为负,说明该元素重复。
function findDuplicate4(nums: number[]): number {
for (let i = 0; i < nums.length; i++) {
const index = Math.abs(nums[i]);
if (nums[index] < 0) {
return index;
}
nums[index] *= -1;
}
return -1;
}
时间复杂度: (O(n))
空间复杂度: (O(1))
5. 重构哈希法
使用数组元素值映射到索引上,通过交换确保每个元素放在正确的位置上,检测重复。
function findDuplicate5(nums: number[]): number {
for (let i = 0; i < nums.length; i++) {
const hash = nums[i] - 1;
if (hash === i) {
continue;
}
if (nums[i] !== nums[hash]) {
[nums[i], nums[hash]] = [nums[hash], nums[i]];
} else {
return nums[i];
}
}
return -1;
}
时间复杂度: (O(n))
空间复杂度: (O(1))
6. 异或法
通过异或操作找到重复元素。
function findDuplicate6(nums: number[]): number {
let res = 0;
for (let i = 0; i < nums.length; i++) {
res ^= i ^ nums[i];
}
return res;
}
时间复杂度: (O(n))
空间复杂度: (O(1))
总结
不同方法的时间和空间复杂度如下:
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 哈希表解法 | (O(n)) | (O(n)) |
| 快慢指针解法 | (O(n)) | (O(1)) |
| 二分查找解法 | (O(n \log n)) | (O(1)) |
| 原地修改解法 | (O(n)) | (O(1)) |
| 重构哈希法 | (O(n)) | (O(1)) |
| 异或法 | (O(n)) | (O(1)) |
实验二:分治法(Leetcode #268、#378)
#268丢失的数字
给定一个包含 [0, n] 中 n 个数的数组 nums ,找出 [0, n] 这个范围内没有出现在数组中的那个数。
示例 1:
输入:nums = [3,0,1]
输出:2
解释:n = 3,因为有 3 个数字,所以所有的数字都在范围 [0,3] 内。2 是丢失的数字,因为它没有出现在 nums 中。
示例 2:
输入:nums = [0,1]
输出:2
解释:n = 2,因为有 2 个数字,所以所有的数字都在范围 [0,2] 内。2 是丢失的数字,因为它没有出现在 nums 中。
示例 3:
输入:nums = [9,6,4,2,3,5,7,0,1]
输出:8
解释:n = 9,因为有 9 个数字,所以所有的数字都在范围 [0,9] 内。8 是丢失的数字,因为它没有出现在 nums 中。
示例 4:
输入:nums = [0]
输出:1
解释:n = 1,因为有 1 个数字,所以所有的数字都在范围 [0,1] 内。1 是丢失的数字,因为它没有出现在 nums 中。
提示:
n == nums.length1 <= n <= 1040 <= nums[i] <= nnums中的所有数字都 独一无二
题目解析:
1. 使用辅助数组
利用一个辅助数组 arr 来记录每个数字是否出现过,最后扫描一遍 arr 找出未出现的数字。
function missingNumber1(nums: number[]): number {
const arr: number[] = new Array(nums.length + 1).fill(0);
for (const num of nums) {
arr[num] = 1;
}
for (let i = 0; i < arr.length; i++) {
if (arr[i] === 0) {
return i;
}
}
return -1;
}
时间复杂度: (O(n))
空间复杂度: (O(n))
2. 求和法
计算 [0, n] 的总和,再减去数组中所有数字的和,得到丢失的数字。
function missingNumber2(nums: number[]): number {
const n = nums.length;
return nums.reduce((prev, curr) => prev - curr, (n * (n + 1)) / 2);
}
时间复杂度: (O(n))
空间复杂度: (O(1))
3. 排序法
先对数组进行排序,然后检查每个位置的数字是否等于其索引值。
function missingNumber3(nums: number[]): number {
nums.sort((a, b) => a - b);
for (let i = 0; i < nums.length; i++) {
if (nums[i] !== i) {
return i;
}
}
return nums.length;
}
时间复杂度: (O(n \log n))
空间复杂度: (O(1))(不考虑排序使用的额外空间)
4. 异或法
利用异或的性质(相同为0,不同为1)来找出丢失的数字。
function missingNumber4(nums: number[]): number {
let res = nums.length;
for (let i = 0; i < nums.length; i++) {
res ^= i ^ nums[i];
}
return res;
}
时间复杂度: (O(n))
空间复杂度: (O(1))
5. 分治求和法
通过分治法计算数组中所有数字的和,再用总和减去数组的和,得到丢失的数字。
function missingNumber5(nums: number[]): number {
const n = nums.length;
let sum = getSum(nums, 0, n - 1);
return (n * (n + 1)) / 2 - sum;
}
const getSum = (nums: number[], left: number, right: number): number => {
if (left === right) {
return nums[left];
}
let sum = 0;
const mid = left + Math.floor((right - left) / 2);
sum += getSum(nums, left, mid);
sum += getSum(nums, mid + 1, right);
return sum;
};
时间复杂度: (O(n \log n))(分治法递归调用)
空间复杂度: (O(\log n))(递归栈空间)
总结
不同方法的时间和空间复杂度如下:
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 使用辅助数组 | (O(n)) | (O(n)) |
| 求和法 | (O(n)) | (O(1)) |
| 排序法 | (O(n \log n)) | (O(1)) |
| 异或法 | (O(n)) | (O(1)) |
| 分治求和法 | (O(n \log n)) | (O(\log n)) |
#378有序矩阵中第K小的元素
给你一个 n x n 矩阵 matrix ,其中每行和每列元素均按升序排序,找到矩阵中第 k 小的元素。
请注意,它是 排序后 的第 k 小元素,而不是第 k 个 不同 的元素。
你必须找到一个内存复杂度优于 O(n2) 的解决方案。
示例 1:
输入:matrix = [[1,5,9],[10,11,13],[12,13,15]], k = 8
输出:13
解释:矩阵中的元素为 [1,5,9,10,11,12,13,13,15],第 8 小元素是 13
示例 2:
输入:matrix = [[-5]], k = 1
输出:-5
提示:
n == matrix.lengthn == matrix[i].length1 <= n <= 300-109 <= matrix[i][j] <= 109- 题目数据 保证
matrix中的所有行和列都按 非递减顺序 排列 1 <= k <= n2
题目解析:
1. 二分查找法
通过二分查找确定第 k 小的元素。二分查找的范围从矩阵的最小值到最大值。在每次二分时,计算有多少个元素小于等于中间值 mid,根据计数调整二分查找的范围。
function kthSmallest(matrix: number[][], k: number): number {
const n = matrix.length;
let left = matrix[0][0];
let right = matrix[n - 1][n - 1];
while (left < right) {
const mid = left + Math.floor((right - left) / 2);
if (check(matrix, mid, k, n)) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}
function check(matrix: number[][], mid: number, k: number, n: number): boolean {
let i = n - 1;
let j = 0;
let num = 0;
while (i >= 0 && j < n) {
if (matrix[i][j] <= mid) {
num += i + 1;
j++;
} else {
i--;
}
}
return num >= k;
}
时间复杂度: (O(n \log(max - min)))
空间复杂度: (O(1))
2. 优先队列法
使用优先队列(最小堆)来存储矩阵元素。每次取出最小元素,并将该元素的右邻和下邻加入队列,重复 k 次后取出第 k 小元素。
class PriorityQueue<T> {
private items: { element: T; priority: number }[];
constructor() {
this.items = [];
}
enqueue(element: T, priority: number): void {
const queueElement = { element, priority };
let added = false;
for (let i = 0; i < this.items.length; i++) {
if (queueElement.priority < this.items[i].priority) {
this.items.splice(i, 0, queueElement);
added = true;
break;
}
}
if (!added) {
this.items.push(queueElement);
}
}
dequeue(): T | undefined {
if (this.isEmpty()) {
return undefined;
}
return this.items.shift()?.element;
}
front(): T | undefined {
if (this.isEmpty()) {
return undefined;
}
return this.items[0].element;
}
isEmpty(): boolean {
return this.items.length === 0;
}
size(): number {
return this.items.length;
}
}
function kthSmallest1(matrix: number[][], k: number): number {
const n = matrix.length;
const pq = new PriorityQueue<number>();
for (let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
pq.enqueue(matrix[i][j], matrix[i][j]);
}
}
let res = 0;
for (let i = 0; i < k; i++) {
res = pq.dequeue()!;
}
return res;
}
时间复杂度: (O(n^2 \log n^2))
空间复杂度: (O(n^2))
3. 大根堆法
使用大根堆来维护当前的前 k 小元素。当堆的大小超过 k 时,移除堆顶元素。最后,堆顶元素即为第 k 小的元素。
class MaxHeap<T> {
private heap: T[];
constructor() {
this.heap = [];
}
private parent(index: number): number {
return Math.floor((index - 1) / 2);
}
private leftChild(index: number): number {
return 2 * index + 1;
}
private rightChild(index: number): number {
return 2 * index + 2;
}
private swap(index1: number, index2: number): void {
[this.heap[index1], this.heap[index2]] = [
this.heap[index2],
this.heap[index1],
];
}
private heapifyUp(index: number): void {
while (index > 0) {
const parentIndex = this.parent(index);
if (this.heap[index] > this.heap[parentIndex]) {
this.swap(index, parentIndex);
index = parentIndex;
} else {
break;
}
}
}
private heapifyDown(index: number): void {
const size = this.heap.length;
while (this.leftChild(index) < size) {
let largest = index;
const left = this.leftChild(index);
const right = this.rightChild(index);
if (left < size && this.heap[left] > this.heap[largest]) {
largest = left;
}
if (right < size && this.heap[right] > this.heap[largest]) {
largest = right;
}
if (largest !== index) {
this.swap(index, largest);
index = largest;
} else {
break;
}
}
}
push(value: T): void {
this.heap.push(value);
this.heapifyUp(this.heap.length - 1);
}
pop(): T | undefined {
if (this.heap.length === 0) {
return undefined;
}
const root = this.heap[0];
const end = this.heap.pop();
if (this.heap.length > 0 && end !== undefined) {
this.heap[0] = end;
this.heapifyDown(0);
}
return root;
}
peek(): T | undefined {
return this.heap.length > 0 ? this.heap[0] : undefined;
}
size(): number {
return this.heap.length;
}
}
function kthSmallest2(matrix: number[][], k: number): number {
const maxHeap = new MaxHeap<number>();
for (let i = 0; i < matrix.length; i++) {
for (let j = 0; j < matrix[i].length; j++) {
maxHeap.push(matrix[i][j]);
if (maxHeap.size() > k) {
maxHeap.pop();
}
}
}
return maxHeap.peek()!;
}
时间复杂度: (O(n^2 \log k))
空间复杂度: (O(k))
总结
不同方法的时间和空间复杂度如下:
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 二分查找法 | (O(n \log(max - min))) | (O(1)) |
| 优先队列法 | (O(n^2 \log n^2)) | (O(n^2)) |
| 大根堆法 | (O(n^2 \log k)) | (O(k)) |
实验三:动态规划(Leetcode #322、#416)
#322 零钱兑换
给你一个整数数组 coins ,表示不同面额的硬币;以及一个整数 amount ,表示总金额。
计算并返回可以凑成总金额所需的 最少的硬币个数 。如果没有任何一种硬币组合能组成总金额,返回 -1 。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
示例 2:
输入:coins = [2], amount = 3
输出:-1
示例 3:
输入:coins = [1], amount = 0
输出:0
提示:
1 <= coins.length <= 121 <= coins[i] <= 231 - 10 <= amount <= 104
题目解析:
1. 动态规划法
动态规划的核心思想是通过构建一个数组 dp,其中 dp[i] 表示凑成金额 i 所需的最少硬币数。通过迭代更新这个数组,可以得出所需结果。
实现思路
- 初始化一个长度为
amount + 1的数组dp,并将所有值设为Infinity,表示初始状态下无法凑成这些金额。 - 设置
dp[0] = 0,因为凑成金额0所需的硬币数为0。 - 遍历每一个金额
i,对于每一个硬币coin,如果i - coin不小于0,则更新dp[i]为dp[i - coin] + 1和dp[i]的最小值。 - 返回
dp[amount]的值,如果其仍为Infinity,则返回-1,表示无法凑成该金额。
function coinChange(coins: number[], amount: number): number {
const dp: number[] = new Array(amount + 1).fill(Infinity);
dp[0] = 0;
for (let i = 1; i <= amount; i++) {
for (const coin of coins) {
if (i - coin >= 0) {
dp[i] = Math.min(dp[i], dp[i - coin] + 1);
}
}
}
return dp[amount] === Infinity ? -1 : dp[amount];
}
时间复杂度: (O(n \times m)),其中 (n) 是 amount,(m) 是 coins 的长度。
空间复杂度: (O(n)),需要一个大小为 amount + 1 的数组。
2. 递归法(带备忘录)
使用递归的方法解决零钱兑换问题。为了避免重复计算,通过备忘录记录已经计算过的结果。
实现思路
- 定义一个递归函数
dp(coins, amount, memo),返回凑成amount所需的最少硬币数。 - 如果
amount为0,返回0,表示无需硬币。 - 如果
amount小于0,返回-1,表示无法凑成该金额。 - 检查备忘录
memo,如果memo[amount]不为0,则直接返回该值,表示之前计算过。 - 初始化结果
res为Infinity。 - 对于每一个硬币
coin,递归计算dp(coins, amount - coin, memo),并更新结果res。 - 将
res保存到备忘录memo中。 - 返回
memo[amount],如果res为Infinity,则返回-1。
function coinChange1(coins: number[], amount: number): number {
const memo: number[] = new Array(amount + 1).fill(0);
return dp(coins, amount, memo);
}
function dp(coins: number[], amount: number, memo: number[]): number {
if (amount === 0) {
return 0;
}
if (amount < 0) {
return -1;
}
if (memo[amount] !== 0) {
return memo[amount];
}
let res = Infinity;
for (const coin of coins) {
const sub = dp(coins, amount - coin, memo);
if (sub === -1) {
continue;
}
res = Math.min(res, sub + 1);
}
memo[amount] = res === Infinity ? -1 : res;
return memo[amount];
}
时间复杂度: 最坏情况下为 (O(n \times m)),其中 (n) 是 amount,(m) 是 coins 的长度。
空间复杂度: (O(n)),需要一个大小为 amount + 1 的备忘录数组。
总结
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 动态规划法 | (O(n \times m)) | (O(n)) |
| 递归法(带备忘录) | (O(n \times m)) | (O(n)) |
#416 分割等和子集
给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
示例 1:
输入:nums = [1,5,11,5]
输出:true
解释:数组可以分割成 [1, 5, 5] 和 [11] 。
示例 2:
输入:nums = [1,2,3,5]
输出:false
解释:数组不能分割成两个元素和相等的子集。
提示:
1 <= nums.length <= 2001 <= nums[i] <= 100
题目解析:
方法1:动态规划法
动态规划法可以将问题转化为一个背包问题,即在给定的数列中找到一个子集,使得其和等于总和的一半。
实现思路
- 计算数组的总和
sum,如果sum是奇数,则无法分割成两个和相等的子集,返回false。 - 计算目标值
target = sum / 2,即背包问题的容量。 - 初始化一个长度为
target + 1的布尔数组dp,其中dp[i]表示是否存在一个子集,其和等于i。 - 初始化
dp[0] = true,因为和为0的子集是存在的(空集)。 - 遍历每一个数
num,从target到num进行逆向遍历,更新dp数组:dp[j] = dp[j] || dp[j - num]
- 返回
dp[target]的值。
function canPartition(nums: number[]): boolean {
const sum = nums.reduce((acc, cur) => acc + cur, 0);
// 如果和为奇数,不可能分割成两个和相等的集合
if (sum % 2 !== 0) return false;
// 转换为背包问题,背包容量为 sum / 2
const target = sum / 2;
// dp[i] 表示容量为 i 的背包能否正好装下 nums 的某几个数
const dp: boolean[] = new Array(target + 1).fill(false);
// base case
dp[0] = true;
// 转移方程:dp[j] = dp[j] || dp[j - num]
for (const num of nums) {
for (let j = target; j >= num; j--) {
dp[j] = dp[j] || dp[j - num];
}
}
// 返回结果
return dp[target];
}
时间复杂度: (O(n \times \text{target})),其中 (n) 是 nums 的长度,target 是数组总和的一半。
空间复杂度: (O(\text{target})),需要一个大小为 target + 1 的数组。
方法2:递归 + 记忆化搜索
使用递归和记忆化搜索的方法,可以通过递归判断是否存在子集使得其和等于目标值,并用记忆化来避免重复计算。
实现思路
- 计算数组的总和
sum,如果sum是奇数,则无法分割成两个和相等的子集,返回false。 - 计算目标值
target = sum / 2。 - 初始化一个二维数组
memo,大小为nums.lengthxtarget + 1,用以记录计算结果。 - 定义一个递归函数
dfs,参数为当前索引index和剩余目标值currentSum:- 基本情况:如果
currentSum为0,返回true。如果index超出数组范围,返回false。 - 如果
memo[index][currentSum]不为undefined,返回该值。 - 递归计算不选择当前数和选择当前数的情况,并记录结果到
memo。
- 基本情况:如果
- 返回
dfs(0, target)的结果。
function canPartition1(nums: number[]): boolean {
const sum = nums.reduce((acc, cur) => acc + cur, 0);
if (sum % 2 !== 0) return false;
const target = sum / 2;
const memo: boolean[][] = Array.from({ length: nums.length }, () => Array(target + 1).fill(undefined));
function dfs(index: number, currentSum: number): boolean {
if (currentSum === 0) return true;
if (index >= nums.length || currentSum < 0) return false;
if (memo[index][currentSum] !== undefined) return memo[index][currentSum];
const notChoose = dfs(index + 1, currentSum);
const choose = dfs(index + 1, currentSum - nums[index]);
memo[index][currentSum] = notChoose || choose;
return memo[index][currentSum];
}
return dfs(0, target);
}
时间复杂度: 最坏情况下为 (O(n \times \text{target})),其中 (n) 是 nums 的长度,target 是数组总和的一半。
空间复杂度: (O(n \times \text{target})),需要一个大小为 nums.length x target + 1 的记忆化数组。
总结
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 动态规划法 | (O(n \times \text{target})) | (O(\text{target})) |
| 递归 + 记忆化搜索 | 最坏情况下 (O(n \times \text{target})) | (O(n \times \text{target})) |
实验四:贪心方法(Leetcode #55、 #455)
#55 跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
提示:
1 <= nums.length <= 1040 <= nums[i] <= 105
题目解析:
方法1:贪心算法
贪心算法通过维护一个最大可达位置 maxReach,遍历数组,更新 maxReach,并检查当前位置是否超过 maxReach 来决定是否可以继续跳跃。
实现思路
- 初始化
maxReach为0。 - 遍历数组中的每个元素
nums[i]:- 如果当前位置
i超过maxReach,返回false。 - 更新
maxReach为max(maxReach, i + nums[i])。
- 如果当前位置
- 如果遍历完成后,
maxReach大于等于数组的最后一个位置,返回true。
function canJump(nums: number[]): boolean {
let maxReach = 0;
for (let i = 0; i < nums.length; i++) {
if (i > maxReach) return false;
maxReach = Math.max(maxReach, i + nums[i]);
}
return maxReach >= nums.length - 1;
}
时间复杂度: (O(n)),其中 (n) 是数组的长度。
空间复杂度: (O(1)),只需要常数空间存储 maxReach。
方法2:动态规划法
动态规划法通过构建一个布尔数组 dp,其中 dp[i] 表示是否能够到达位置 i。然后遍历数组更新 dp 数组。
实现思路
- 初始化一个布尔数组
dp,长度为nums.length,所有元素初始化为false。 - 将
dp[0]设为true,因为初始位置总是可达的。 - 遍历数组,对于每一个位置
i,如果dp[i]为true,则将i位置之后的nums[i]个位置设为true。 - 遍历完成后,返回
dp[nums.length - 1]。
function canJumpDP(nums: number[]): boolean {
const dp = new Array(nums.length).fill(false);
dp[0] = true;
for (let i = 0; i < nums.length; i++) {
if (dp[i]) {
for (let j = 1; j <= nums[i] && i + j < nums.length; j++) {
dp[i + j] = true;
}
}
}
return dp[nums.length - 1];
}
时间复杂度: (O(n^2)),最坏情况下,每个位置都需要遍历其之后的 nums[i] 个位置。
空间复杂度: (O(n)),需要一个大小为 nums.length 的布尔数组。
方法3:回溯法
回溯法尝试从起始位置递归地跳跃到可能的位置,直到找到一个成功的路径或遍历完所有可能性。
实现思路
- 定义一个递归函数
canJumpFromPosition,参数为当前位置position。 - 如果当前位置为最后一个位置,返回
true。 - 计算可以跳跃的最远位置
furthestJump = min(position + nums[position], nums.length - 1)。 - 从当前位置
position到furthestJump,递归调用canJumpFromPosition。 - 如果任何一个递归调用返回
true,返回true,否则返回false。
function canJumpBacktrack(nums: number[]): boolean {
function canJumpFromPosition(position: number): boolean {
if (position === nums.length - 1) return true;
const furthestJump = Math.min(position + nums[position], nums.length - 1);
for (let nextPosition = position + 1; nextPosition <= furthestJump; nextPosition++) {
if (canJumpFromPosition(nextPosition)) {
return true;
}
}
return false;
}
return canJumpFromPosition(0);
}
时间复杂度: 最坏情况下 (O(2^n)),其中 (n) 是数组的长度。
空间复杂度: (O(n)),递归调用的栈深度为 nums.length。
总结
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 贪心算法 | (O(n)) | (O(1)) |
| 动态规划法 | (O(n^2)) | (O(n)) |
| 回溯法 | 最坏情况下 (O(2^n)) | (O(n)) |
#455 分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
提示:
1 <= g.length <= 3 * 1040 <= s.length <= 3 * 1041 <= g[i], s[j] <= 231 - 1
题目解析:
方法1:贪心算法
贪心算法通过首先将孩子的胃口值和饼干的尺寸排序,然后使用双指针遍历数组,以确保每次都用尽可能小的饼干去满足胃口最小的孩子。
实现思路
- 将孩子的胃口值数组
g和饼干尺寸数组s进行排序。 - 使用两个指针
i和j分别指向孩子和饼干数组的开头。 - 遍历饼干数组,如果当前饼干能满足当前孩子的胃口,则将孩子指针和饼干指针都右移;否则只移动饼干指针。
- 遍历完成后,孩子指针的值即为能满足的孩子数量。
function findContentChildren(g: number[], s: number[]): number {
// 按照胃口和饼干大小排序
g.sort((a, b) => a - b);
s.sort((a, b) => a - b);
let i = 0; // 孩子指针
for (let j = 0; j < s.length; j++) {
if (i < g.length && s[j] >= g[i]) {
i++;
}
}
return i;
}
时间复杂度: (O(n \log n + m \log m)),其中 (n) 和 (m) 分别是 g 和 s 的长度,排序操作的时间复杂度为 (O(n \log n)) 和 (O(m \log m))。
空间复杂度: (O(1)),只需要常数空间存储指针 i 和 j。
方法2:模拟分配算法
可以通过模拟分配的方式来满足尽可能多的孩子,虽然复杂度会更高,但可以通过简单的逻辑实现。
实现思路
- 将孩子的胃口值数组
g进行排序。 - 对于每一个孩子,从饼干数组中寻找满足其胃口值的最小饼干。
- 如果找到合适的饼干,则将其从饼干数组中移除,并记录满足的孩子数量。
function findContentChildrenSimulate(g: number[], s: number[]): number {
// 按照胃口排序
g.sort((a, b) => a - b);
let count = 0; // 满足的孩子数量
for (let i = 0; i < g.length; i++) {
for (let j = 0; j < s.length; j++) {
if (s[j] >= g[i]) {
count++;
s.splice(j, 1); // 移除满足条件的饼干
break;
}
}
}
return count;
}
时间复杂度: (O(n^2)),其中 (n) 是 g 的长度,模拟分配每个孩子时需要遍历饼干数组,最坏情况下需要 (O(n \times m))。
空间复杂度: (O(1)),除了输入数组外,只需常数空间存储 count。
总结
| 方法 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 贪心算法 | (O(n \log n + m \log m)) | (O(1)) |
| 模拟分配算法 | (O(n^2)) | (O(1)) |
实验5
题目介绍:
2020 年华中科技大学计算机科学与技术学院
研究生入学考试复试专业实践能力考核试题
本质上是一个集合覆盖问题
集合覆盖问题
集合覆盖问题(Set Cover Problem)是计算机科学和数学中的一个经典问题,属于NP完全问题。它可以用来描述很多实际生活中的优化问题,如选址问题、资源分配问题等。具体定义如下:
给定一个集合 (U) (称为“全集”)和一个集合族 (S = \{S_1, S_2, \ldots, S_n\}),其中每个 ( S_i ) 是 ( U ) 的子集。集合覆盖问题要求找出一个最小的子集 (C \subseteq S),使得这些子集的并集等于全集 ( U )。换句话说,就是在集合族 (S) 中找到最少数量的子集,使得它们的并集覆盖了全集 (U)。
形式化的定义如下:
- 输入:一个全集 (U) 和一个集合族 (S = \{S_1, S_2, \ldots, S_n\})。
- 输出:一个子集 (C \subseteq S),使得 (\bigcup_{S_i \in C} S_i = U) 且 (|C|) 最小。
这个问题的一个例子是:
- 全集 (U = \{1, 2, 3, 4, 5\})。
- 集合族 (S = \{\{1, 2, 3\}, \{2, 4\}, \{3, 4, 5\}, \{4, 5\}\})。
要找到最小的子集 (C),使得 (C) 中的元素的并集覆盖全集 (U)。在这个例子中,一个可能的最优解是 (C = \{\{1, 2, 3\}, \{4, 5\}\}),因为这两个子集的并集覆盖了全集 (\{1, 2, 3, 4, 5\})。
由于集合覆盖问题是NP完全问题,目前没有已知的多项式时间算法能够在所有情况下找到最优解。然而,可以使用贪心算法得到一个近似解,该算法在实践中通常表现良好。
贪心算法
贪心算法是一类算法设计范式,旨在通过逐步构建解决方案,在每一步选择当前局部最优的选择,从而希望最终得到全局最优解。贪心算法的关键在于它的贪心选择性质,即每一步都做出一个当前看来最好的选择,不考虑未来可能带来的影响。
贪心算法的基本思想
贪心算法的一般步骤如下:
- 初始化:构建一个初始解,通常是一个空解。
- 迭代选择:在每一步中,选择一个当前最优的选项,并将其加入解中。
- 更新状态:更新当前解的状态,准备进行下一步选择。
- 终止条件:重复步骤2和3,直到达到问题的约束条件或终止条件。
贪心算法解决集合覆盖问题
在集合覆盖问题中,给定一个集合 (U)(称为全集)和一个集合族 (S = \{S_1, S_2, \ldots, S_n\}),每个 (S_i) 是 (U) 的子集。目标是找到最小的子集族 (C \subseteq S),使得这些子集的并集等于全集 (U)。
使用贪心算法解决集合覆盖问题的步骤如下:
- 初始化:定义覆盖集合 (C = \emptyset) 和未覆盖元素集合 (U' = U)。
- 迭代选择:重复以下步骤,直到 (U') 为空:
- 从集合族 (S) 中选择一个集合 (S_i),该集合能覆盖 (U') 中最多的未覆盖元素。
- 将 (S_i) 加入覆盖集合 (C)。
- 更新未覆盖元素集合 (U'),即从 (U') 中去掉 (S_i) 所覆盖的元素。
- 输出:最终的覆盖集合 (C)。
贪心算法的步骤详解
输入:
- 全集 (U)。
- 集合族 (S = \{S_1, S_2, \ldots, S_n\})。
输出:
- 最小的覆盖集合 (C \subseteq S)。
算法:
def greedy_set_cover(U, S):
C = [] # 初始化覆盖集合
U_prime = set(U) # 初始化未覆盖元素集合
while U_prime:
# 选择能覆盖最多未覆盖元素的集合
best_set = max(S, key=lambda s: len(U_prime & s))
# 将选择的集合加入覆盖集合
C.append(best_set)
# 更新未覆盖元素集合
U_prime -= best_set
return C
# 示例
U = {1, 2, 3, 4, 5}
S = [{1, 2, 3}, {2, 4}, {3, 4, 5}, {4, 5}]
cover = greedy_set_cover(U, S)
print("覆盖集合:", cover)
解释:
- 初始化:定义覆盖集合 (C) 为空,并初始化未覆盖元素集合 (U') 为全集 (U)。
- 迭代选择:
- 使用
max函数和一个lambda表达式选择集合族 (S) 中能覆盖最多未覆盖元素的集合 (S_i)。 - 将选择的集合 (S_i) 加入覆盖集合 (C)。
- 使用集合操作从未覆盖元素集合 (U') 中去掉 (S_i) 所覆盖的元素。
- 使用
- 输出:当未覆盖元素集合 (U') 为空时,输出最终的覆盖集合 (C)。
示例解析
以示例 (U = \{1, 2, 3, 4, 5\}) 和 (S = \{\{1, 2, 3\}, \{2, 4\}, \{3, 4, 5\}, \{4, 5\}\}) 为例:
- 初始状态:(U' = \{1, 2, 3, 4, 5\}),(C = [])。
- 选择 (\{1, 2, 3\}),因为它覆盖最多未覆盖元素:(\{1, 2, 3\})。
- 更新 (U' = \{4, 5\}),(C = [\{1, 2, 3\}])。
- 选择 (\{4, 5\}),因为它覆盖最多未覆盖元素:(\{4, 5\})。
- 更新 (U' = \emptyset),(C = [\{1, 2, 3\}, \{4, 5\}])。
- 终止条件满足,输出 (C)。
贪心算法的性能
- 时间复杂度:每一步选择集合的操作需要遍历所有集合,因此时间复杂度为 (O(nm)),其中 (n) 是集合数量,(m) 是全集元素数量。
- 近似度:贪心算法不能保证最优解,但在最坏情况下,解的近似度在 (\log n) 范围内,即最坏情况下,解的大小最多是最优解的 (\log n) 倍。
贪心算法简单高效,适合大多数实际应用中的集合覆盖问题,但在某些特殊情况下可能无法得到最优解。
题目解析:
输入用例:
2 4 // 表示有2个元素(地点),4个集合(摄像头)
0 // 第一个元素是0
3 // 元素0被三个集合覆盖
1 2 3 // 覆盖元素0的集合编号是1、2、3
1 // 第二个元素是1
2 // 元素1被两个集合覆盖
0 2 // 覆盖元素1的集合编号是0、2
-
第一行的两个数,分别表示元素(地点)的数量和集合(摄像头)的数量。
之后,每一个元素(地点)的信息包含三行:
- 第一行是元素的编号。
- 第二行是覆盖这个元素的集合的数量。
- 第三行是覆盖这个元素的集合的编号。
-
在输入用例中,我们得到的是针对某个元素(地点),被哪几个集合(摄像头)覆盖的信息。
-
而我们想要将其以集合覆盖问题来解决,我们需要的信息是
- 集合(摄像头)
覆盖了哪些元素(地点)
- 集合(摄像头)
-
所以我们的输入内容需要被适当解析。
输入处理
void readDataFromFile() {
ifstream inputFile("../SetCoveringRealData/SC01.txt");
if (!inputFile) {
cerr << "SC02.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
inputFile >> totalCameras >> totalPlaces;
for (int i = 0; i < totalCameras; ++i) {
int cameraID, numPlaces;
inputFile >> cameraID >> numPlaces;
for (int j = 0; j < numPlaces; ++j) {
int placeID;
inputFile >> placeID;
cameraCoverageMap[cameraID].insert(placeID);
}
}
// 初始化未覆盖地点集合
for (const auto& [_, set] : cameraCoverageMap) {
uncoveredPlaces.insert(set.begin(), set.end());
}
inputFile.close();
cout << "数据读取完成!" << endl;
}
函数解析
readDataFromFile 函数的目的是从文件中读取数据,并将其转换为便于处理的形式。主要步骤如下:
-
打开文件:
ifstream inputFile("../SetCoveringRealData/SC01.txt"); if (!inputFile) { cerr << "SC02.txt 不存在" << endl; exit(EXIT_FAILURE); }- 尝试打开指定路径的文件。如果文件无法打开,输出错误信息并退出程序。
-
读取总数信息:
inputFile >> totalCameras >> totalPlaces;- 读取文件的第一行,获取元素(地点)的数量和集合(摄像头)的数量,分别存入
totalCameras和totalPlaces。
- 读取文件的第一行,获取元素(地点)的数量和集合(摄像头)的数量,分别存入
-
读取元素信息并构建覆盖关系:
for (int i = 0; i < totalCameras; ++i) { int cameraID, numPlaces; inputFile >> cameraID >> numPlaces; for (int j = 0; j < numPlaces; ++j) { int placeID; inputFile >> placeID; cameraCoverageMap[cameraID].insert(placeID); } }- 使用一个循环来读取每一个元素的信息。
- 对于每一个元素,读取其编号和被覆盖的集合的数量。
- 再次循环,读取覆盖该元素的集合编号,并将这些关系存入
cameraCoverageMap,其中键是集合编号,值是覆盖的元素集合。
-
初始化未覆盖地点集合:
for (const auto& [_, set] : cameraCoverageMap) { uncoveredPlaces.insert(set.begin(), set.end()); }- 遍历
cameraCoverageMap,将所有覆盖的元素加入到uncoveredPlaces集合中。这样我们可以初始化出所有待覆盖的元素集合。
- 遍历
-
关闭文件并输出完成信息:
inputFile.close(); cout << "数据读取完成!" << endl;- 关闭文件并打印数据读取完成的消息。
处理结果
经过以上步骤,最终得到的数据结构如下:
-
cameraCoverageMap:- 一个
map,键是集合(摄像头)的编号,值是一个set,包含了该集合所覆盖的元素(地点)的编号。例如,假设从输入读取得到以下信息:cameraCoverageMap = { 0: {1}, 1: {0}, 2: {0, 1}, 3: {0} }
- 一个
-
uncoveredPlaces:- 一个
set,包含所有待覆盖的元素。例如:uncoveredPlaces = {0, 1}
- 一个
贪心计算
void calculateMinimumCover() {
ofstream outputFile("../greedy-Out1-real.txt");
if (!outputFile) {
cerr << "Out1.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
std::cout << "开始计算最小覆盖..." << endl;
// 迭代直到所有地点被覆盖
while (!uncoveredPlaces.empty()) {
int bestCamera = -1; // 覆盖最多未覆盖地点的摄像头ID
set<int> bestCoverage; // 最佳摄像头覆盖的地点集合
size_t maxCoverage = 0; // 单个摄像头覆盖的最多未覆盖地点数
// 找到覆盖最多未覆盖地点的最佳摄像头
for (const auto& [camera, places] : cameraCoverageMap) {
set<int> currentCoverage;
set_intersection(
places.begin(), places.end(), uncoveredPlaces.begin(),
uncoveredPlaces.end(),
inserter(currentCoverage, currentCoverage.begin()));
if (currentCoverage.size() > maxCoverage) {
maxCoverage = currentCoverage.size();
bestCamera = camera;
bestCoverage = move(currentCoverage);
}
}
// 从映射中移除最佳摄像头
cameraCoverageMap.erase(bestCamera);
// 更新未覆盖地点集合,移除被最佳摄像头覆盖的地点
set<int> newUncoveredPlaces;
set_difference(
uncoveredPlaces.begin(), uncoveredPlaces.end(),
bestCoverage.begin(), bestCoverage.end(),
inserter(newUncoveredPlaces, newUncoveredPlaces.begin()));
uncoveredPlaces = move(newUncoveredPlaces);
// 将最佳摄像头加入结果集合
selectedCameras.insert(bestCamera);
// 输出当前点覆盖率
std::cout << "\r当前覆盖率: " << (totalPlaces - uncoveredPlaces.size())
<< '/' << totalPlaces;
}
std::cout << endl;
// 输出结果
outputFile << selectedCameras.size() << '\n';
for (const int camera : selectedCameras) {
outputFile << camera << ' ';
}
outputFile.close();
std::cout << "计算完成!" << std::endl;
}
详细流程及分析
函数 calculateMinimumCover 的目的是使用贪心算法计算最小的集合覆盖。该算法通过迭代地选择能覆盖最多未覆盖元素的集合来实现。以下是每个步骤的详细流程和分析:
-
打开输出文件:
ofstream outputFile("../greedy-Out1-real.txt"); if (!outputFile) { cerr << "Out1.txt 不存在" << endl; exit(EXIT_FAILURE); }- 打开输出文件。如果文件无法打开,则输出错误信息并退出程序。
-
输出开始计算的消息:
std::cout << "开始计算最小覆盖..." << endl;- 输出计算开始的提示信息。
-
初始化变量:
while (!uncoveredPlaces.empty()) { int bestCamera = -1; // 覆盖最多未覆盖地点的摄像头ID set<int> bestCoverage; // 最佳摄像头覆盖的地点集合 size_t maxCoverage = 0; // 单个摄像头覆盖的最多未覆盖地点数bestCamera用于存储当前迭代中覆盖最多未覆盖元素的集合的ID。bestCoverage用于存储当前迭代中最佳集合所覆盖的元素集合。maxCoverage用于记录当前迭代中最佳集合覆盖的未覆盖元素的数量。
-
寻找覆盖最多未覆盖地点的最佳摄像头:
for (const auto& [camera, places] : cameraCoverageMap) { set<int> currentCoverage; set_intersection( places.begin(), places.end(), uncoveredPlaces.begin(), uncoveredPlaces.end(), inserter(currentCoverage, currentCoverage.begin())); if (currentCoverage.size() > maxCoverage) { maxCoverage = currentCoverage.size(); bestCamera = camera; bestCoverage = move(currentCoverage); } }- 遍历
cameraCoverageMap中的每个摄像头及其覆盖的地点集合。 - 使用
set_intersection函数计算当前摄像头覆盖的未覆盖元素(即currentCoverage)。 - 如果
currentCoverage的大小大于maxCoverage,则更新maxCoverage,并将bestCamera设置为当前摄像头ID,bestCoverage更新为currentCoverage。
- 遍历
-
移除最佳摄像头并更新未覆盖地点集合:
cameraCoverageMap.erase(bestCamera); set<int> newUncoveredPlaces; set_difference( uncoveredPlaces.begin(), uncoveredPlaces.end(), bestCoverage.begin(), bestCoverage.end(), inserter(newUncoveredPlaces, newUncoveredPlaces.begin())); uncoveredPlaces = move(newUncoveredPlaces);- 从
cameraCoverageMap中移除最佳摄像头。 - 使用
set_difference函数计算未被最佳摄像头覆盖的地点,并更新uncoveredPlaces。
- 从
-
将最佳摄像头加入结果集合:
selectedCameras.insert(bestCamera);- 将最佳摄像头ID加入
selectedCameras集合中。
- 将最佳摄像头ID加入
-
输出当前点覆盖率:
std::cout << "\r当前覆盖率: " << (totalPlaces - uncoveredPlaces.size()) << '/' << totalPlaces;- 输出当前覆盖率,即已覆盖的地点数与总地点数的比例。
-
输出最终结果:
std::cout << endl; outputFile << selectedCameras.size() << '\n'; for (const int camera : selectedCameras) { outputFile << camera << ' '; } outputFile.close(); std::cout << "计算完成!" << std::endl;- 将最终结果输出到文件和控制台。
- 输出摄像头的数量。
- 输出所有选中的摄像头ID。
- 关闭输出文件并打印计算完成的消息。
完整代码
#include <algorithm>
#include <chrono>
#include <fstream>
#include <iostream>
#include <iterator>
#include <set>
#include <unordered_map>
using namespace std;
using namespace std::chrono;
unordered_map<int, set<int>>
cameraCoverageMap; // 摄像头ID到其覆盖地点集合的映射
set<int> uncoveredPlaces, selectedCameras; // 未覆盖地点集合和选中的摄像头集合
int totalCameras, totalPlaces; // 摄像头和地点的总数
void readDataFromFile() {
ifstream inputFile("../SetCoveringRealData/SC01.txt");
if (!inputFile) {
cerr << "SC02.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
inputFile >> totalCameras >> totalPlaces;
for (int i = 0; i < totalCameras; ++i) {
int cameraID, numPlaces;
inputFile >> cameraID >> numPlaces;
for (int j = 0; j < numPlaces; ++j) {
int placeID;
inputFile >> placeID;
cameraCoverageMap[cameraID].insert(placeID);
}
}
// 初始化未覆盖地点集合
for (const auto& [_, set] : cameraCoverageMap) {
uncoveredPlaces.insert(set.begin(), set.end());
}
inputFile.close();
cout << "数据读取完成!" << endl;
}
void calculateMinimumCover() {
ofstream outputFile("../greedy-Out1-real.txt");
if (!outputFile) {
cerr << "Out1.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
std::cout << "开始计算最小覆盖..." << endl;
// 迭代直到所有地点被覆盖
while (!uncoveredPlaces.empty()) {
int bestCamera = -1; // 覆盖最多未覆盖地点的摄像头ID
set<int> bestCoverage; // 最佳摄像头覆盖的地点集合
size_t maxCoverage = 0; // 单个摄像头覆盖的最多未覆盖地点数
// 找到覆盖最多未覆盖地点的最佳摄像头
for (const auto& [camera, places] : cameraCoverageMap) {
set<int> currentCoverage;
set_intersection(
places.begin(), places.end(), uncoveredPlaces.begin(),
uncoveredPlaces.end(),
inserter(currentCoverage, currentCoverage.begin()));
if (currentCoverage.size() > maxCoverage) {
maxCoverage = currentCoverage.size();
bestCamera = camera;
bestCoverage = move(currentCoverage);
}
}
// 从映射中移除最佳摄像头
cameraCoverageMap.erase(bestCamera);
// 更新未覆盖地点集合,移除被最佳摄像头覆盖的地点
set<int> newUncoveredPlaces;
set_difference(
uncoveredPlaces.begin(), uncoveredPlaces.end(),
bestCoverage.begin(), bestCoverage.end(),
inserter(newUncoveredPlaces, newUncoveredPlaces.begin()));
uncoveredPlaces = move(newUncoveredPlaces);
// 将最佳摄像头加入结果集合
selectedCameras.insert(bestCamera);
// 输出当前点覆盖率
std::cout << "\r当前覆盖率: " << (totalPlaces - uncoveredPlaces.size())
<< '/' << totalPlaces;
}
std::cout << endl;
// 输出结果
outputFile << selectedCameras.size() << '\n';
for (const int camera : selectedCameras) {
outputFile << camera << ' ';
}
outputFile.close();
std::cout << "计算完成!" << std::endl;
}
int main() {
auto start = high_resolution_clock::now(); // 记录开始时间
std::cout << "开始运行!" << std::endl;
// 读取数据
readDataFromFile();
// 计算最小覆盖
calculateMinimumCover();
auto end = high_resolution_clock::now(); // 记录结束时间
auto duration =
duration_cast<milliseconds>(end - start).count(); // 计算总运行时间
std::cout << "运行结束! 总运行时间: " << duration << " 毫秒" << std::endl;
return 0;
}
使用自定义数据结构代替map和set
#include <algorithm>
#include <chrono>
#include <fstream>
#include <iostream>
#include <iterator>
#include <vector>
using namespace std;
using namespace std::chrono;
struct Camera {
int id;
int numPlaces;
int* places; // 动态数组,用于存储覆盖的地点ID
};
// 摄像头覆盖的集合
Camera* cameras;
bool* uncoveredPlaces;
int* selectedCameras;
int totalCameras, totalPlaces;
int numSelectedCameras = 0;
void readDataFromFile() {
ifstream inputFile("../SetCoveringRealData/SC01.txt");
if (!inputFile) {
cerr << "SC01.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
inputFile >> totalCameras >> totalPlaces;
cameras = new Camera[totalCameras];
uncoveredPlaces = new bool[totalPlaces + 1](); // 初始化为false
for (int i = 0; i < totalCameras; ++i) {
int cameraID, numPlaces;
inputFile >> cameraID >> numPlaces;
cameras[i].id = cameraID;
cameras[i].numPlaces = numPlaces;
cameras[i].places = new int[numPlaces];
for (int j = 0; j < numPlaces; ++j) {
int placeID;
inputFile >> placeID;
cameras[i].places[j] = placeID;
uncoveredPlaces[placeID] = true; // 标记为未覆盖
}
}
inputFile.close();
cout << "数据读取完成!" << endl;
}
void calculateMinimumCover() {
ofstream outputFile("../greedy-Out1-real.txt");
if (!outputFile) {
cerr << "greedy-Out1-real.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
cout << "开始计算最小覆盖..." << endl;
selectedCameras = new int[totalCameras];
// 迭代直到所有地点被覆盖
while (true) {
int bestCamera = -1; // 覆盖最多未覆盖地点的摄像头ID
int* bestCoverage = nullptr; // 最佳摄像头覆盖的地点集合
size_t maxCoverage = 0; // 单个摄像头覆盖的最多未覆盖地点数
// 找到覆盖最多未覆盖地点的最佳摄像头
for (int i = 0; i < totalCameras; ++i) {
if (cameras[i].places == nullptr) continue;
size_t currentCoverage = 0;
for (int j = 0; j < cameras[i].numPlaces; ++j) {
if (uncoveredPlaces[cameras[i].places[j]]) {
++currentCoverage;
}
}
if (currentCoverage > maxCoverage) {
maxCoverage = currentCoverage;
bestCamera = i;
bestCoverage = cameras[i].places;
}
}
if (bestCamera == -1) break; // 无可选择摄像头
// 标记被最佳摄像头覆盖的地点
for (int i = 0; i < cameras[bestCamera].numPlaces; ++i) {
uncoveredPlaces[cameras[bestCamera].places[i]] = false;
}
// 将最佳摄像头加入结果集合
selectedCameras[numSelectedCameras++] = cameras[bestCamera].id;
// 删除最佳摄像头
delete[] cameras[bestCamera].places;
cameras[bestCamera].places = nullptr;
// 输出当前点覆盖率
int uncoveredCount = 0;
for (int i = 1; i <= totalPlaces; ++i) {
if (uncoveredPlaces[i]) ++uncoveredCount;
}
cout << "\r当前覆盖率: " << (totalPlaces - uncoveredCount) << '/' << totalPlaces;
}
cout << endl;
// 输出结果
outputFile << numSelectedCameras << '\n';
for (int i = 0; i < numSelectedCameras; ++i) {
outputFile << selectedCameras[i] << ' ';
}
outputFile.close();
cout << "计算完成!" << endl;
// 释放内存
for (int i = 0; i < totalCameras; ++i) {
delete[] cameras[i].places;
}
delete[] cameras;
delete[] uncoveredPlaces;
delete[] selectedCameras;
}
int main() {
auto start = high_resolution_clock::now(); // 记录开始时间
cout << "开始运行!" << endl;
// 读取数据
readDataFromFile();
// 计算最小覆盖
calculateMinimumCover();
auto end = high_resolution_clock::now(); // 记录结束时间
auto duration = duration_cast<milliseconds>(end - start).count(); // 计算总运行时间
cout << "运行结束! 总运行时间: " << duration << " 毫秒" << endl;
return 0;
}
Camera 结构体的必要性
在这个问题中,Camera 结构体被用来表示每个摄像头及其覆盖的地点信息。这个结构体包含三个成员:
id: 摄像头的ID。numPlaces: 该摄像头覆盖的地点数量。places: 动态数组,存储该摄像头覆盖的地点ID。
通过使用 Camera 结构体,我们可以将与摄像头相关的数据集中到一个地方,便于管理和访问。这有助于简化代码的逻辑,提高可读性和维护性。
主要修改及性能提升
-
数据读取和存储:
- 通过
Camera结构体,所有摄像头信息存储在一个动态数组cameras中,而不是使用map来存储摄像头和覆盖的地点集合。 - 将覆盖的地点信息存储为一个动态数组而非
set,减少了在读取数据时的动态内存分配和哈希操作,提升了性能。
struct Camera { int id; int numPlaces; int* places; // 动态数组,用于存储覆盖的地点ID }; Camera* cameras; bool* uncoveredPlaces; int* selectedCameras; - 通过
-
未覆盖地点的存储:
- 使用布尔数组
uncoveredPlaces来标记地点是否未被覆盖,取代了set。这种方式节省了内存,并且在检查地点是否被覆盖时,时间复杂度从O(log n)降低到O(1)。
uncoveredPlaces = new bool[totalPlaces + 1](); // 初始化为false - 使用布尔数组
-
寻找最佳摄像头:
- 遍历摄像头时,直接访问摄像头的动态数组
places,并计算当前摄像头覆盖的未覆盖地点数量。这一过程避免了set的遍历和插入操作。
size_t currentCoverage = 0; for (int j = 0; j < cameras[i].numPlaces; ++j) { if (uncoveredPlaces[cameras[i].places[j]]) { ++currentCoverage; } } if (currentCoverage > maxCoverage) { maxCoverage = currentCoverage; bestCamera = i; bestCoverage = cameras[i].places; } - 遍历摄像头时,直接访问摄像头的动态数组
-
标记和删除最佳摄像头:
- 标记最佳摄像头覆盖的地点为已覆盖,删除摄像头的动态数组,并将其指针置为
nullptr,避免重复计算。
for (int i = 0; i < cameras[bestCamera].numPlaces; ++i) { uncoveredPlaces[cameras[bestCamera].places[i]] = false; } delete[] cameras[bestCamera].places; cameras[bestCamera].places = nullptr; - 标记最佳摄像头覆盖的地点为已覆盖,删除摄像头的动态数组,并将其指针置为
-
输出结果:
- 将选中的摄像头ID存储在动态数组
selectedCameras中,并在最后输出。
outputFile << numSelectedCameras << '\n'; for (int i = 0; i < numSelectedCameras; ++i) { outputFile << selectedCameras[i] << ' '; } - 将选中的摄像头ID存储在动态数组
-
内存管理:
- 使用动态数组代替STL容器,通过显式内存分配和释放来管理内存。这种方式虽然增加了代码的复杂性,但减少了STL容器的开销,提高了性能。
delete[] cameras; delete[] uncoveredPlaces; delete[] selectedCameras;
总结
通过这些修改,代码在以下方面提升了性能:
- 时间复杂度:使用数组和布尔标记,减少了复杂的数据结构操作,提高了访问速度。
- 空间复杂度:减少了STL容器的内存开销,采用紧凑的数据结构存储信息。
- 内存管理:显式地管理内存,避免了不必要的动态分配和释放。
使用多线程优化
#include <algorithm>
#include <chrono>
#include <fstream>
#include <iostream>
#include <iterator>
#include <mutex>
#include <thread>
#include <vector>
using namespace std;
using namespace std::chrono;
struct Camera {
int id;
int numPlaces;
int* places; // 动态数组,用于存储覆盖的地点ID
};
// 摄像头覆盖的集合
Camera* cameras;
bool* uncoveredPlaces;
int* selectedCameras;
int totalCameras, totalPlaces;
int numSelectedCameras = 0;
/**
* @brief 从文件中读取数据
* 读取数据并初始化摄像头和未覆盖地点集合
*/
void readDataFromFile() {
ifstream inputFile("../SetCoveringRealData/SC01.txt");
if (!inputFile) {
cerr << "SC01.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
inputFile >> totalCameras >> totalPlaces;
cameras = new Camera[totalCameras];
uncoveredPlaces = new bool[totalPlaces + 1](); // 初始化为false
for (int i = 0; i < totalCameras; ++i) {
int cameraID, numPlaces;
inputFile >> cameraID >> numPlaces;
cameras[i].id = cameraID;
cameras[i].numPlaces = numPlaces;
cameras[i].places = new int[numPlaces];
for (int j = 0; j < numPlaces; ++j) {
int placeID;
inputFile >> placeID;
cameras[i].places[j] = placeID;
uncoveredPlaces[placeID] = true; // 标记为未覆盖
}
}
inputFile.close();
cout << "数据读取完成!" << endl;
}
/**
* @brief 找到覆盖最多未覆盖地点的摄像头
* 从指定范围内找到覆盖最多未覆盖地点的摄像头
* @param start 搜索范围的起始索引
* @param end 搜索范围的结束索引
* @param localBestCamera 用于保存局部最佳摄像头ID
* @param localMaxCoverage 用于保存局部最大覆盖地点数
* @param localBestCoverage 用于保存局部最佳覆盖地点集合
*/
void findBestCamera(int start, int end, int& localBestCamera,
size_t& localMaxCoverage, int* localBestCoverage) {
localBestCamera = -1;
localMaxCoverage = 0;
for (int i = start; i < end; ++i) {
if (cameras[i].places == nullptr) continue;
size_t currentCoverage = 0;
for (int j = 0; j < cameras[i].numPlaces; ++j) {
if (uncoveredPlaces[cameras[i].places[j]]) {
++currentCoverage;
}
}
if (currentCoverage > localMaxCoverage) {
localMaxCoverage = currentCoverage;
localBestCamera = i;
}
}
}
/**
* @brief 计算最小覆盖
* 从所有摄像头中选择覆盖最多未覆盖地点的摄像头,直到所有地点被覆盖
*/
void calculateMinimumCover() {
ofstream outputFile("../greedy-Out1-real.txt");
if (!outputFile) {
cerr << "greedy-Out1-real.txt 不存在" << endl;
exit(EXIT_FAILURE);
}
cout << "开始计算最小覆盖..." << endl;
selectedCameras = new int[totalCameras];
unsigned int numThreads = thread::hardware_concurrency();
cout << "线程数: " << numThreads << endl;
vector<thread> threads(numThreads);
vector<int> localBestCameras(numThreads, -1);
vector<size_t> localMaxCoverages(numThreads, 0);
vector<int*> localBestCoverages(numThreads, nullptr);
// 迭代直到所有地点被覆盖
while (true) {
int bestCamera = -1; // 覆盖最多未覆盖地点的摄像头ID
int* bestCoverage = nullptr; // 最佳摄像头覆盖的地点集合
size_t maxCoverage = 0; // 单个摄像头覆盖的最多未覆盖地点数
int chunkSize = totalCameras / numThreads;
for (unsigned int t = 0; t < numThreads; ++t) {
int start = t * chunkSize;
int end = (t == numThreads - 1) ? totalCameras : start + chunkSize;
threads[t] =
thread(findBestCamera, start, end, ref(localBestCameras[t]),
ref(localMaxCoverages[t]), localBestCoverages[t]);
}
for (unsigned int t = 0; t < numThreads; ++t) {
threads[t].join();
}
// 找出全局最佳摄像头
for (unsigned int t = 0; t < numThreads; ++t) {
if (localMaxCoverages[t] > maxCoverage) {
maxCoverage = localMaxCoverages[t];
bestCamera = localBestCameras[t];
}
}
if (bestCamera == -1) break; // 无可选择摄像头
// 标记被最佳摄像头覆盖的地点
for (int i = 0; i < cameras[bestCamera].numPlaces; ++i) {
uncoveredPlaces[cameras[bestCamera].places[i]] = false;
}
// 将最佳摄像头加入结果集合
selectedCameras[numSelectedCameras++] = cameras[bestCamera].id;
// 删除最佳摄像头
delete[] cameras[bestCamera].places;
cameras[bestCamera].places = nullptr;
// 输出当前点覆盖率
int uncoveredCount = 0;
for (int i = 1; i <= totalPlaces; ++i) {
if (uncoveredPlaces[i]) ++uncoveredCount;
}
cout << "\r当前覆盖率: " << (totalPlaces - uncoveredCount) << '/'
<< totalPlaces;
}
cout << endl;
// 输出结果
outputFile << numSelectedCameras << '\n';
for (int i = 0; i < numSelectedCameras; ++i) {
outputFile << selectedCameras[i] << ' ';
}
outputFile.close();
cout << "计算完成!" << endl;
// 释放内存
for (int i = 0; i < totalCameras; ++i) {
delete[] cameras[i].places;
}
delete[] cameras;
delete[] uncoveredPlaces;
delete[] selectedCameras;
}
int main() {
auto start = high_resolution_clock::now(); // 记录开始时间
cout << "开始运行!" << endl;
// 读取数据
readDataFromFile();
// 计算最小覆盖
calculateMinimumCover();
auto end = high_resolution_clock::now(); // 记录结束时间
auto duration =
duration_cast<milliseconds>(end - start).count(); // 计算总运行时间
cout << "运行结束! 总运行时间: " << duration << " 毫秒" << endl;
return 0;
}
多线程优化的原因
在计算机科学中,多线程优化是一种利用多核处理器来提高程序执行效率的技术。多线程优化主要有以下几个好处:
- 性能提升:通过并行处理多个任务,可以大幅度减少程序的执行时间。
- 资源利用最大化:现代处理器通常具有多个核心,多线程可以让程序充分利用这些核心,从而提高资源利用率。
- 响应性提高:在图形用户界面(GUI)应用程序中,多线程可以提高应用程序的响应性,使得界面在后台进行复杂计算时仍然保持流畅。
多线程优化的注意点
- 线程安全:在多线程环境下,多个线程可能会同时访问共享资源,需要通过锁机制(如
mutex)来确保线程安全。 - 任务分解:需要合理地将任务分解为多个子任务,以便于在不同线程上并行执行。
- 负载均衡:确保每个线程分配的任务量大致相同,避免某些线程过载,而其他线程空闲的情况。
- 数据同步:需要考虑线程之间的数据同步问题,确保线程之间的数据一致性。
适合多线程优化的问题
- 独立任务:每个任务可以独立执行,不依赖其他任务的结果。
- 大规模数据处理:如排序、大数据分析、图像处理等,数据量大,处理过程可以并行化。
- 计算密集型任务:如科学计算、机器学习训练等,计算量大且可以分解为多个独立计算任务。
多线程优化实现
这段代码使用了多线程来优化寻找覆盖最多未覆盖地点的摄像头过程。具体实现如下:
-
读取数据和初始化:
- 读取摄像头和地点的覆盖信息,初始化
cameras数组和uncoveredPlaces数组。
void readDataFromFile() { ifstream inputFile("../SetCoveringRealData/SC01.txt"); if (!inputFile) { cerr << "SC01.txt 不存在" << endl; exit(EXIT_FAILURE); } inputFile >> totalCameras >> totalPlaces; cameras = new Camera[totalCameras]; uncoveredPlaces = new bool[totalPlaces + 1](); // 初始化为false for (int i = 0; i < totalCameras; ++i) { int cameraID, numPlaces; inputFile >> cameraID >> numPlaces; cameras[i].id = cameraID; cameras[i].numPlaces = numPlaces; cameras[i].places = new int[numPlaces]; for (int j = 0; j < numPlaces; ++j) { int placeID; inputFile >> placeID; cameras[i].places[j] = placeID; uncoveredPlaces[placeID] = true; // 标记为未覆盖 } } inputFile.close(); cout << "数据读取完成!" << endl; } - 读取摄像头和地点的覆盖信息,初始化
-
多线程寻找最佳摄像头:
- 使用多个线程并行查找覆盖最多未覆盖地点的摄像头。每个线程处理一部分摄像头,通过分块处理提高效率。
void findBestCamera(int start, int end, int& localBestCamera, size_t& localMaxCoverage, int* localBestCoverage) { localBestCamera = -1; localMaxCoverage = 0; for (int i = start; i < end; ++i) { if (cameras[i].places == nullptr) continue; size_t currentCoverage = 0; for (int j = 0; j < cameras[i].numPlaces; ++j) { if (uncoveredPlaces[cameras[i].places[j]]) { ++currentCoverage; } } if (currentCoverage > localMaxCoverage) { localMaxCoverage = currentCoverage; localBestCamera = i; } } } -
主计算循环:
- 主计算循环中,通过创建多个线程并行执行
findBestCamera函数,找到覆盖最多未覆盖地点的摄像头。然后合并结果,选择最佳摄像头进行覆盖。
void calculateMinimumCover() { ofstream outputFile("../greedy-Out1-real.txt"); if (!outputFile) { cerr << "greedy-Out1-real.txt 不存在" << endl; exit(EXIT_FAILURE); } cout << "开始计算最小覆盖..." << endl; selectedCameras = new int[totalCameras]; unsigned int numThreads = thread::hardware_concurrency(); cout << "线程数: " << numThreads << endl; vector<thread> threads(numThreads); vector<int> localBestCameras(numThreads, -1); vector<size_t> localMaxCoverages(numThreads, 0); vector<int*> localBestCoverages(numThreads, nullptr); while (true) { int bestCamera = -1; int* bestCoverage = nullptr; size_t maxCoverage = 0; int chunkSize = totalCameras / numThreads; for (unsigned int t = 0; t < numThreads; ++t) { int start = t * chunkSize; int end = (t == numThreads - 1) ? totalCameras : start + chunkSize; threads[t] = thread(findBestCamera, start, end, ref(localBestCameras[t]), ref(localMaxCoverages[t]), localBestCoverages[t]); } for (unsigned int t = 0; t < numThreads; ++t) { threads[t].join(); } for (unsigned int t = 0; t < numThreads; ++t) { if (localMaxCoverages[t] > maxCoverage) { maxCoverage = localMaxCoverages[t]; bestCamera = localBestCameras[t]; } } if (bestCamera == -1) break; for (int i = 0; i < cameras[bestCamera].numPlaces; ++i) { uncoveredPlaces[cameras[bestCamera].places[i]] = false; } selectedCameras[numSelectedCameras++] = cameras[bestCamera].id; delete[] cameras[bestCamera].places; cameras[bestCamera].places = nullptr; int uncoveredCount = 0; for (int i = 1; i <= totalPlaces; ++i) { if (uncoveredPlaces[i]) ++uncoveredCount; } cout << "\r当前覆盖率: " << (totalPlaces - uncoveredCount) << '/' << totalPlaces; } cout << endl; outputFile << numSelectedCameras << '\n'; for (int i = 0; i < numSelectedCameras; ++i) { outputFile << selectedCameras[i] << ' '; } outputFile.close(); cout << "计算完成!" << endl; for (int i = 0; i < totalCameras; ++i) { delete[] cameras[i].places; } delete[] cameras; delete[] uncoveredPlaces; delete[] selectedCameras; } - 主计算循环中,通过创建多个线程并行执行
-
主函数:
- 主函数中,记录程序运行时间,并调用数据读取和计算函数。
int main() { auto start = high_resolution_clock::now(); // 记录开始时间 cout << "开始运行!" << endl; readDataFromFile(); calculateMinimumCover(); auto end = high_resolution_clock::now(); // 记录结束时间 auto duration = duration_cast<milliseconds>(end - start).count(); // 计算总运行时间 cout << "运行结束! 总运行时间: " << duration << " 毫秒" << endl; return 0; }
最终运行结果:
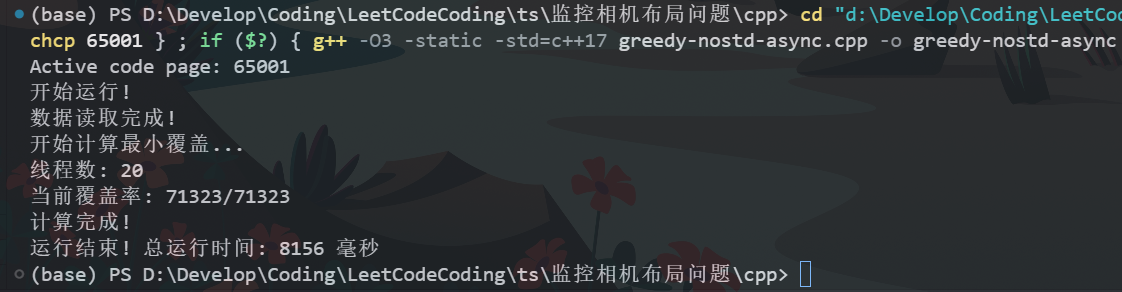
使用Java实现上述代码
单线程基础版本
public class SetCoveringAlgorithm {
static Map<Integer, Set<Integer>> cameraCoverageMap = new HashMap<>();
static Set<Integer> uncoveredPlaces = new HashSet<>();
static Set<Integer> selectedCameras = new HashSet<>();
static int totalCameras, totalPlaces;
public static void readDataFromFile() throws IOException {
File inputFile = new File("./SC02.txt");
Scanner scanner = new Scanner(new FileInputStream(inputFile));
totalCameras = scanner.nextInt();
totalPlaces = scanner.nextInt();
for (int i = 0; i < totalCameras; ++i) {
int cameraID = scanner.nextInt();
int numPlaces = scanner.nextInt();
Set<Integer> places = new HashSet<>();
for (int j = 0; j < numPlaces; ++j) {
int placeID = scanner.nextInt();
places.add(placeID);
}
cameraCoverageMap.put(cameraID, places);
uncoveredPlaces.addAll(places);
}
scanner.close();
System.out.println("数据读取完成!");
}
public static void calculateMinimumCover() throws IOException {
PrintWriter outputFile = new PrintWriter(new FileOutputStream("./greedy-Out2.txt"));
while (!uncoveredPlaces.isEmpty()) {
int bestCamera = -1;
Set<Integer> bestCoverage = new HashSet<>();
int maxCoverage = 0;
for (Map.Entry<Integer, Set<Integer>> entry : cameraCoverageMap.entrySet()) {
int camera = entry.getKey();
Set<Integer> places = entry.getValue();
Set<Integer> currentCoverage = new HashSet<>(places);
currentCoverage.retainAll(uncoveredPlaces);
if (currentCoverage.size() > maxCoverage) {
maxCoverage = currentCoverage.size();
bestCamera = camera;
bestCoverage = currentCoverage;
}
}
cameraCoverageMap.remove(bestCamera);
uncoveredPlaces.removeAll(bestCoverage);
selectedCameras.add(bestCamera);
}
outputFile.println(selectedCameras.size());
for (int camera : selectedCameras) {
outputFile.print(camera + " ");
}
outputFile.close();
System.out.println("计算完成!");
}
public static void main(String[] args) throws IOException {
long start = System.currentTimeMillis();
System.out.println("开始运行!");
readDataFromFile();
calculateMinimumCover();
long end = System.currentTimeMillis();
long duration = end - start;
System.out.println("运行结束! 总运行时间: " + duration + " 毫秒");
}
}
多线程优化版本
public class SetCoveringAlgorithmAsync {
// 结果类,用于存储每个摄像头的覆盖结果
static class CameraCoverageResult {
int cameraID;
int coverageSize;
Set<Integer> coverage;
CameraCoverageResult(int cameraID, int coverageSize, Set<Integer> coverage) {
this.cameraID = cameraID;
this.coverageSize = coverageSize;
this.coverage = coverage;
}
}
static String inputFilename;
static String outputFilename;
// 摄像头覆盖地点映射
static Map<Integer, Set<Integer>> cameraCoverageMap = new HashMap<>();
// 未覆盖地点集合
static Set<Integer> uncoveredPlaces = new HashSet<>();
// 选中摄像头集合
static Set<Integer> selectedCameras = new HashSet<>();
// 摄像头总数和地点总数
static int totalCameras, totalPlaces;
// 线程池
static ExecutorService executor;
public static void readDataFromFile() throws IOException {
File inputFile = new File(inputFilename);
Scanner scanner = new Scanner(new FileInputStream(inputFile));
totalCameras = scanner.nextInt();
totalPlaces = scanner.nextInt();
for (int i = 0; i < totalCameras; ++i) {
int cameraID = scanner.nextInt();
int numPlaces = scanner.nextInt();
Set<Integer> places = new HashSet<>();
for (int j = 0; j < numPlaces; ++j) {
int placeID = scanner.nextInt();
places.add(placeID);
}
cameraCoverageMap.put(cameraID, places);
uncoveredPlaces.addAll(places);
}
scanner.close();
System.out.println("数据读取完成!");
}
public static void calculateMinimumCover() throws IOException, InterruptedException, ExecutionException {
System.out.println("开始计算最小覆盖集合...\n");
PrintWriter outputFile = new PrintWriter(new FileOutputStream(outputFilename));
// 计算计算耗时
long start = System.currentTimeMillis();
while (!uncoveredPlaces.isEmpty()) {
List<Callable<CameraCoverageResult>> tasks = new ArrayList<>();
for (Map.Entry<Integer, Set<Integer>> entry : cameraCoverageMap.entrySet()) {
int camera = entry.getKey();
Set<Integer> places = entry.getValue();
Callable<CameraCoverageResult> task = () -> {
Set<Integer> currentCoverage = new HashSet<>(places);
currentCoverage.retainAll(uncoveredPlaces);
return new CameraCoverageResult(camera, currentCoverage.size(), currentCoverage);
};
tasks.add(task);
}
// 提交所有任务
List<Future<CameraCoverageResult>> futures = executor.invokeAll(tasks);
int bestCamera = -1;
Set<Integer> bestCoverage = new HashSet<>();
int maxCoverage = 0;
// 处理每个任务的结果
for (Future<CameraCoverageResult> future : futures) {
CameraCoverageResult result = future.get();
if (result.coverageSize > maxCoverage) {
maxCoverage = result.coverageSize;
bestCamera = result.cameraID;
bestCoverage = result.coverage;
}
}
// 更新未覆盖地点和选中摄像头集合
cameraCoverageMap.remove(bestCamera);
uncoveredPlaces.removeAll(bestCoverage);
selectedCameras.add(bestCamera);
//输出当前点覆盖率
System.out.print("\r当前覆盖率: " + (totalPlaces - uncoveredPlaces.size()) + " / " + totalPlaces);
}
// 输出结果
outputFile.println(selectedCameras.size());
for (int camera : selectedCameras) {
outputFile.print(camera + " ");
}
outputFile.close();
System.out.println("计算完成!");
// 计算耗时
long end = System.currentTimeMillis();
long duration = end - start;
System.out.println("计算耗时: " + duration + " 毫秒");
}
public static void main(String[] args) throws IOException, InterruptedException {
// 初始化线程池
int numThreads = Runtime.getRuntime().availableProcessors();
// int numThreads = 4;
System.out.println("当前有 " + numThreads + " 个线程参与计算");
executor = Executors.newFixedThreadPool(numThreads);
inputFilename = "./SC01.txt";
outputFilename = "./greedy-async-Out1-real.txt";
long start = System.currentTimeMillis();
System.out.println("开始运行!");
readDataFromFile();
try {
calculateMinimumCover();
} catch (ExecutionException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
long duration = end - start;
System.out.println("运行结束! 总运行时间: " + duration + " 毫秒");
// 关闭线程池
executor.shutdown();
}
}
使用Python实现上述代码
-
为什么Python代码没有多线程?
Python 缺少多线程支持是由于全局解释器锁 (GIL)导致的。GIL 是一种保证一次只有一个线程可以执行 Python 字节码的机制。从本质上讲,这意味着即使 Python 进程中可以存在多个线程,它们也不能并发执行 Python 代码。 这是因为 GIL 将解释器限制为单个线程,这会阻止其他线程执行 Python 代码。
全局解释器锁的存在是因为 Python 采用了引用计数内存管理模型,当对象的引用计数为零时,它会删除对象。 GIL 保证即便是多个线程同时访问同一个对象的情况下,引用计数也是准确的。 如果没有 GIL ,就会出现竞争,两个线程可能会同时尝试修改同一对象的引用计数,从而导致诸多内存问题。
理论上可以启用python3.12的Per-Interpreter GIL来获得多线程支持,但是现在3.12并不完善, Per-Interpreter GIL依然是实验性的特性,可能会导致不稳定性和性能问题,故Python版本代码不使用多线程。
import os
import time
class Camera:
def __init__(self, id, num_places, places: list[int]):
self.id = id
self.num_places = num_places
self.places = places
cameras = []
uncovered_places = []
selected_cameras = []
total_cameras = 0
total_places = 0
def read_data_from_file():
global total_cameras, total_places, cameras, uncovered_places
input_file_path = "D:\\Develop\\Coding\\LeetCodeCoding\\ts\\监控相机布局问题\\SetCoveringRealData\\SC01.txt"
if not os.path.exists(input_file_path):
print("SC01.txt 不存在")
exit(1)
with open(input_file_path, 'r') as input_file:
total_cameras, total_places = map(int, input_file.readline().split())
uncovered_places = [False] * (total_places + 1)
for _ in range(total_cameras):
camera_id = int(input_file.readline().strip())
num_places = int(input_file.readline().strip())
places = list(map(int, input_file.readline().split()))
cameras.append(Camera(camera_id, num_places, places))
for place in places:
uncovered_places[place] = True # 标记为未覆盖
print("数据读取完成!")
def calculate_minimum_cover():
global uncovered_places, selected_cameras
output_file_path = "../greedy-Out1-real.txt"
if not os.path.exists(os.path.dirname(output_file_path)):
os.makedirs(os.path.dirname(output_file_path))
print("开始计算最小覆盖...")
num_selected_cameras = 0
# 迭代直到所有地点被覆盖
while True:
best_camera: Camera = None # 覆盖最多未覆盖地点的摄像头
max_coverage = 0 # 单个摄像头覆盖的最多未覆盖地点数
# 找到覆盖最多未覆盖地点的最佳摄像头
for camera in cameras:
if camera.places is None:
continue
current_coverage = sum(1 for place in camera.places if uncovered_places[place])
if current_coverage > max_coverage:
max_coverage = current_coverage
best_camera = camera
if best_camera is None:
break # 无可选择摄像头
# 标记被最佳摄像头覆盖的地点
for place in best_camera.places:
uncovered_places[place] = False
# 将最佳摄像头加入结果集合
selected_cameras.append(best_camera.id)
num_selected_cameras += 1
# 删除最佳摄像头
best_camera.places = None
# 输出当前点覆盖率
uncovered_count = sum(uncovered_places[1:total_places + 1])
print(f"\r当前覆盖率: {total_places - uncovered_count}/{total_places}", end='')
print()
# 输出结果
with open(output_file_path, 'w') as output_file:
output_file.write(f"{num_selected_cameras}\n")
output_file.write(' '.join(map(str, selected_cameras)))
print("计算完成!")
def main():
start = time.time() # 记录开始时间
print("开始运行!")
# 读取数据
read_data_from_file()
# 计算最小覆盖
calculate_minimum_cover()
end = time.time() # 记录结束时间
duration = (end - start) * 1000 # 计算总运行时间
print(f"运行结束! 总运行时间: {duration:.0f} 毫秒")
if __name__ == "__main__":
main()