
数据库概论期末复习资料
大部分资料来自课本,部分资料来自互联网
[toc]

第一章、绪论
数据库系统概述
数据库的基本概念
数据 Data
一、数据的定义:
数据(Data)
是数据库中存储的 基本对象。
定义:描述事物的符号记录称为 数据
数据的含义称为数据的语义,数据与其语义是不可分的
数据库 DB
一、数据库的定义:
数据库(Database,DB)
数据库是 长期 储存在计算机内,有组织、可共享、大量 的数据集合。
概括的说:数据库数据具有 永久存储、有组织、可共享三个基本特点
二、数据库的特征
- 用
数据模型组织,描述 和 存储 数据; - 数据共享;
- 较小的冗余度(就是一个数据存放多次)
这个要多说一下,计算机存储里同一个数据有多个副本,如果说这个数据需要修改就要把所有的副本值修改,如果冗余度过高,也就意味着源代码中有很多个副本值,一个个修改工作量相当大,而且容易出现遗漏现象,导致运行错误。同样的,冗余度是不能没有的,我们要做的只能是让冗余度尽量小,因为在数据库出问题的时候,需要在副本里修改 bug,所以冗余度的存在是必须的。
- 较高的数据独立性
数据库是提供给用户使用的
不管数据结构怎么变,应用都不变 就是数据独立性的体现。
- 易扩展
保证应用可以在原来的架构上,进行数据优化以达到优化应用功能和画面等作用。(而不是推翻重建)
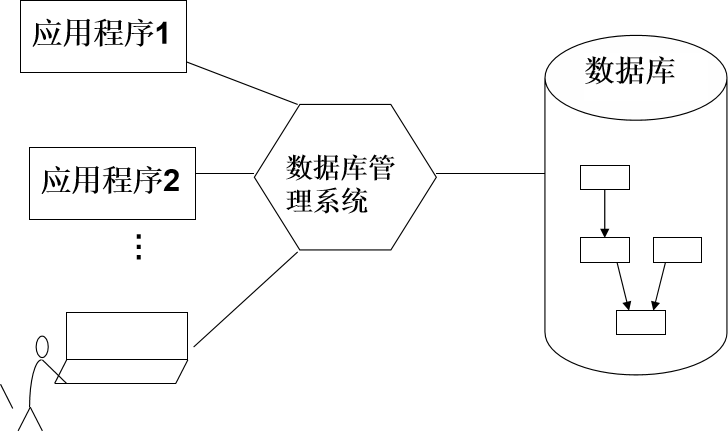
数据库管理系统 DBMS
一、数据库管理系统的定义:
数据库管理系统(Database Management System,DBMS)
数据库管理系统是介于用户和操作系统之间的数据管理软件。
二、数据库管理系统的功能
- 数据定义功能
- 提供
数据定义语言(Data Definition Language,DDL)- 定义数据库中的数据对象
- 数据组织、存储和管理(怎么表达数据)
- 分类组织、存储和管理各种数据
- 确定组织数据的文件结构和存储方式
- 实现数据之间的联系
- 提供多种存取方法(如:索引查找,hash 查找 etc.)以提高存取效率
- 数据操纵功能(怎么运用数据)
- 提供
数据操纵语言(Data Manipulation Language,DML)- 利用 DML 操纵数据实现对数据库的基本操作(增删改查)
- 数据库的事务管理和运行管理
- 保证数据的完整性和安全性(就是说存在后台数据,用户看不到也不能修改)
- 多用户对数据的并发使用(用户之间的数据不能互相影响,相互独立)
- 发生故障后的系统恢复(能够返回到之前某一个)
- 数据库的建立和维护功能
- 初始数据的输入,转换
- 数据库的转储,恢复
- 数据库数据的批量装载
- 数据库的重组织
- 性能监视
- etc.
- 其他功能
- DBMS 与网络中其他软件系统的通信
- DBMS 间的数据转换
- 异构数据库之间的互访与互操作
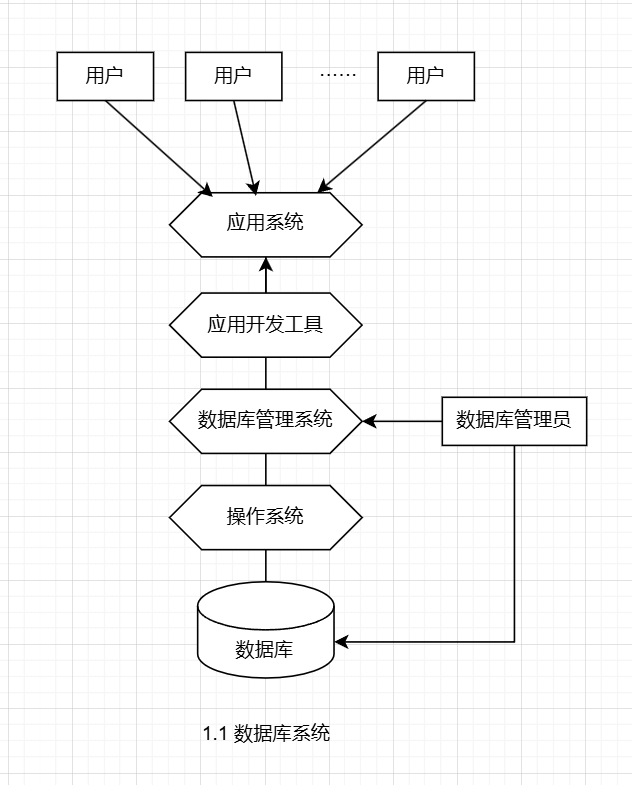
数据库系统 DBS
一、数据库系统的定义:
数据库系统(Database System,DBS)
数据库系统(DBS)包含 数据库、数据库管理系统(以及应用开发工具)、应用程序 和 数据库管理员(DataBase Administrator,DBA)
数据库发展的三个阶段( 了解,对比 )
1、人工管理阶段
特点:
(1)数据量较少
(2)数据不永久保存
(3)没有软件系统对数据进行管理
手工处理数据有两个特点:第一,应用于应用之间的依赖性太强。第二:数据与数据组之间可能有太多重复数据,造成数据 冗余。
如图所示:

2、文件系统阶段
文件系统最大的特点就是解决了应用程序和数据之间的一个公共接口问题,使得应用程序采用统一的存取方法来操作数据。
特点:
(1)数据可以长期保留,数据的逻辑结构和物理结构有了区别,程序可以按名访问,不必关系数据的物理位置,由文件系统提供存取方法。
(2)数据不属于某个特定应用,即应用程序和数据不再是直接的对应关系,可以重复使用。
(3)文件组织形式的多样化,有索引文件,链接文件,Hash 文件等等。
文件系统有以下缺点:
(1)数据冗余。
(2)数据不一致性。
(3)数据孤立,即数据联系弱。
如图所示:

3、数据库系统阶段
特点:
(1)采用复杂的数据模型表示数据结构。数据模型不仅描述数据本身的特点还描述数据之间的联系,数据不再面向某个应用,而是面向整个应用系统。数据冗余明显减少,实现数据共享。
(2)有较高的数据独立性。
如图所示:

参考数据库系统工程师教程第三版。
三个阶段的对比:
| 人工管理阶段 | 文件系统阶段 | 数据库系统阶段 | ||
|---|---|---|---|---|
| 背景 | 应用背景 | 科学计算 | 科学计算、数据管理 | 大规模数据管理 |
| 硬件背景 | 无直接存取存储设备 | 磁盘、磁鼓 | 大容量磁盘、磁盘阵列 | |
| 软件背景 | 没有操作系统 | 有文件系统 | 有数据库管理系统 | |
| 处理方式 | 批处理 | 联机实时处理、批处理 | 联机实时处理、有效处理、批处理 | |
| 特点 | 数据的管理者 | 用户(程序员) | 文件系统 | 数据库管理系统 |
| 数据面向的对象 | 某一应用程序 | 某一应用 | 现实世界(一个部门、企业、跨国组织等) | |
| 数据的共享程度 | 无共享,冗余度极大 | 共享性差,冗余度大 | 共享性高,冗余度小 | |
| 数据的独立性 | 不独立,完全依赖应用程序 | 独立性差 | 具有高度的物理独立性和一定的逻辑独立性 | |
| 数据的结构化 | 无结构 | 记录为单位结构,物理结构多样 | 整体结构化,用数据模型描述 | |
| 数据控制能力 | 应用程序自己控制 | 应用程序自己控制 | 由数据库管理系统提供数据安全性、完整性,并支持控制和恢复能力 |
数据库系统的特点
-
数据结构化
-
数据的整体结构化是数据库的主要特征之一
-
整体结构化
-
不再仅仅针对某一个应用,而是面向全组织
-
不仅数据内部结构化,整体是结构化的,数据之间具有联系
-
数据记录可以变长
-
数据的最小存取单位是数据项
数据的用数据模型描述,无需应用程序定义
-
-
-
数据的共享性高,冗余度低且易扩展
数据面向整个系统,可以被多个用户、多个应用共享使用。
数据共享的好处
- 减少数据冗余,节约存储空间
- 避免数据之间的不相容性与不一致性
- 使系统易于扩充
-
数据独立性高
物理独立性
- 指用户的应用程序与数据库中数据的物理存储是相互独立的。当数据的物理存储改变了,应用程序不用改变。
逻辑独立性
- 指用户的应用程序与数据库的逻辑结构是相互独立的。数据的逻辑结构改变了,应用程序不用改变。
数据独立性由数据库管理系统的二级映像功能来保证。
-
数据由数据库管理系统统一管理和控制
数据库管理系统提供的数据控制功能
- 数据的安全性(Security)保护
- 保护数据以防止不合法的使用造成的数据的泄密和破坏。
- 数据的完整性(Integrity)检查
- 保证数据的正确性、有效性和相容性。
- 并发(Concurrency)控制
- 对多用户的并发操作加以控制和协调,防止相互干扰而得到错误的结果。
- 数据库恢复(Recovery)
- 将数据库从错误状态恢复到某一已知的正确状态。
- 数据的安全性(Security)保护
小结
数据库是长期存储在计算机内有组织的大量的共享的数据集合。
可以供各种用户共享,具有最小冗余度和较高的数据独立性。
数据库管理系统在数据库建立、运用和维护时对数据库进行统一控制,以保证数据的完整性、安全性,并在多用户同时使用数据库时进行并发控制,在发生故障后对数据库进行恢复。
数据模型
数据模型是对现实世界数据特征的抽象。
通俗地讲数据模型就是 现实世界的模拟 。
数据模型应该满足三方面要求
- 能比较 真实地 模拟现实世界
- 容易 为人所 理解
- 便于在计算机上 实现
数据模型是数据库系统的 核心和基础
两类数据模型
数据模型分为两类(两个不同的层次)
-
概念模型
- 也称信息模型,它是按用户的观点来对数据和信息建模,用于数据库设计。
-
逻辑模型和物理模型
- 逻辑模型 主要包括网状模型、层次模型、关系模型、面向对象数据模型、对象关系数据模型、半结构化数据模型等。按计算机系统的观点对数据建模,用于 DBMS 实现。
- 物理模型 是对数据最底层的抽象,描述数据在系统内部的表示方式和存取方法,在磁盘或磁带上的存储方式和存取方法。
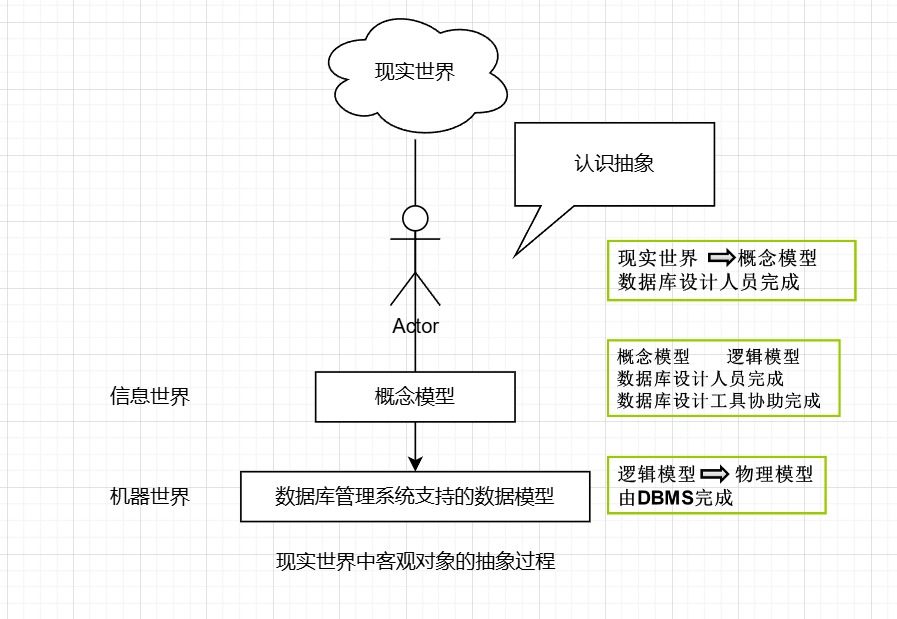
客观对象的抽象过程—两步抽象
-
现实世界中的客观对象抽象为概念模型
- 将现实世界抽象为信息世界
-
把概念模型转换为某一数据库管理系统支持的数据模型
- 将信息世界转换为机器世界
数据库系统的结构
从数据库应用开发人员角度看
数据库系统通常采用三级模式结构,是数据库系统内部的系统结构。
从数据库最终用户角度看
数据库系统的结构分为:
- 单用户结构
- 主从式结构
- 分布式结构
- 客户-服务器结构
- 浏览器-应用服务器 / 数据库服务器多层结构等
数据库系统模式的概念
“型”和“值”的概念
型(Type)
- 对某一类数据的结构和属性的说明
值(Value)
- 是型的一个具体赋值
例如
学生记录:
- (学号,姓名,性别,系别,年龄,籍贯)
一个记录值:
- (201315130,李明,男,计算机系,19,江苏南京市)
模式(Schema)
- 数据库逻辑结构和特征的描述
- 是型的描述,不涉及具体值
- 反映的是数据的结构及其联系
- 模式是相对稳定的
实例(Instance)
- 模式的一个具体值
- 反映数据库某一时刻的状态
- 同一个模式可以有很多实例
- 实例随数据库中的数据的更新而变动
例如
在学生选课数据库模式中,包含学生记录、课程记录和学生选课记录:
2013 年的一个学生数据库实例,包含:
- 2013 年学校中所有学生的记录
- 学校开设的所有课程的记录
- 所有学生选课的记录
2012 年度学生数据库模式对应的实例与 2013 年度学生数据库模式对应的实例是不同的。
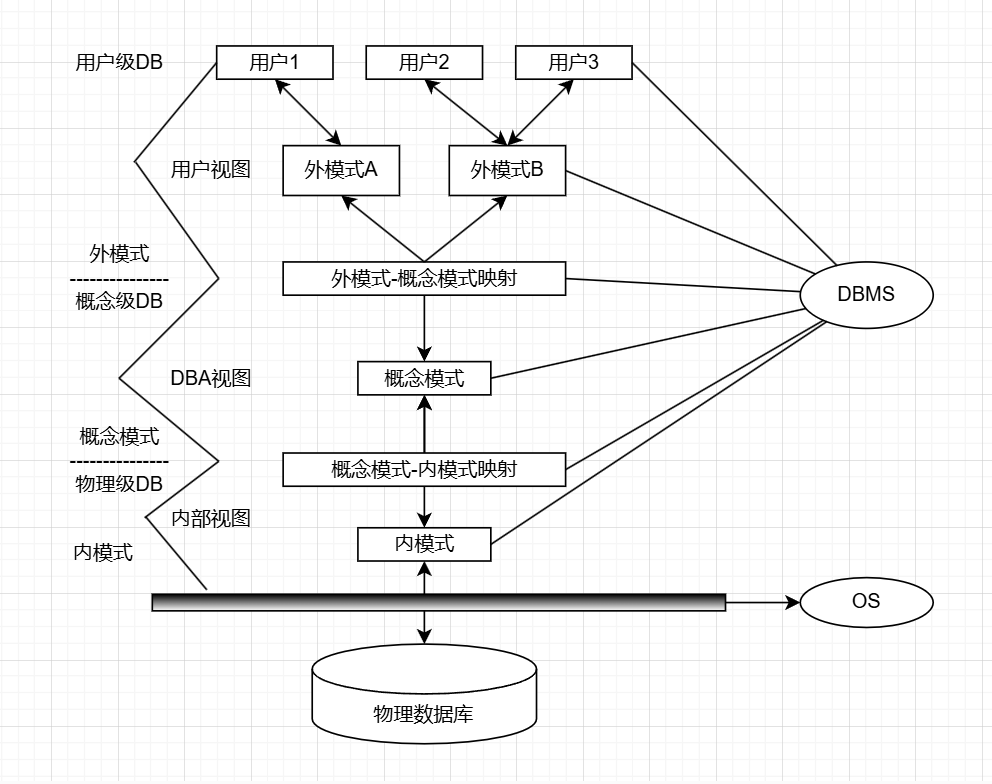
数据库系统的三级模式结构( 重点 )
模式(Schema,也称逻辑模式)
- 定义: 数据库中全体数据的逻辑结构和特征的描述,所有用户的公共数据视图。
- 特点:
- 一个数据库只有一个模式
- 是数据库系统模式结构的中间层
- 与数据的物理存储细节和硬件环境无关
- 与具体的应用程序、开发工具及高级程序设计语言无关
- 内容:
- 数据的逻辑结构(数据项的名字、类型、取值范围等)
- 数据之间的联系
- 数据有关的安全性、完整性要求
外模式(External Schema)
- 定义: 数据库用户(包括应用程序员和最终用户)使用的局部数据的逻辑结构和特征的描述,是数据库用户的数据视图,与某一应用有关的数据的逻辑表示。
- 特点:
- 介于模式与应用之间
- 模式与外模式的关系是一对多
- 外模式通常是模式的子集
- 一个数据库可以有多个外模式,反映不同用户的应用需求、看待数据的方式、对数据保密的要求
- 对模式中同一数据,在外模式中的结构、类型、长度、保密级别等都可以不同
- 外模式与应用的关系是一对多
- 同一外模式可以为某一用户的多个应用系统所使用,但一个应用程序只能使用一个外模式
- 用途:
- 保证数据库安全性的一个有力措施
- 每个用户只能看见和访问所对应的外模式中的数据
内模式(Internal Schema)
- 定义: 是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。
- 内容:
- 记录的存储方式(例如,顺序存储,按照 B 树结构存储,按 hash 方法存储等)
- 索引的组织方式
- 数据是否压缩存储
- 数据是否加密
- 数据存储记录结构的规定
- 特点:
- 一个数据库只有一个内模式
数据库的二级映像功能与数据独立性( 重点 )
三级模式是对数据的三个抽象级别
二级映像在数据库管理系统内部实现这三个抽象层次的联系和转换:
- 外模式/模式映像
- 模式/内模式映像
1. 外模式/模式映像
- 模式: 描述的是数据的全局逻辑结构
- 外模式: 描述的是数据的局部逻辑结构
- 同一个模式可以有任意多个外模式
- 每一个外模式,数据库系统都有一个外模式/模式映像,定义外模式与模式之间的对应关系
- 映像定义通常包含在各自外模式的描述中
保证数据的逻辑独立性
- 当模式改变时,数据库管理员对外模式/模式映像作相应改变,使外模式保持不变
- 应用程序是依据数据的外模式编写的,应用程序不必修改,保证了数据与程序的逻辑独立性,即数据的逻辑独立性
2. 模式/内模式映像
- 定义: 模式/内模式映像定义了数据全局逻辑结构与存储结构之间的对应关系。例如,说明逻辑记录和字段在内部是如何表示的
- 数据库中模式/内模式映像是唯一的
- 该映像定义通常包含在模式描述中
保证数据的物理独立性
- 当数据库的存储结构改变(例如选用了另一种存储结构)时,数据库管理员修改模式/内模式映像,使模式保持不变
- 应用程序不受影响,保证了数据与程序的物理独立性,即数据的物理独立性
总结
数据库模式
- 即全局逻辑结构是数据库的中心与关键
- 独立于数据库的其他层次
- 设计数据库模式结构时应首先确定数据库的逻辑模式
数据库的内模式
- 依赖于它的全局逻辑结构
- 独立于数据库的用户视图,即外模式
- 独立于具体的存储设备
- 将全局逻辑结构中所定义的数据结构及其联系按照一定的物理存储策略进行组织,以达到较好的时间与空间效率
数据库的外模式
- 面向具体的应用程序
- 定义在逻辑模式之上
- 独立于存储模式和存储设备
- 当应用需求发生较大变化,相应外模式不能满足其视图要求时,该外模式就得做相应改动
- 设计外模式时应充分考虑到应用的扩充性
- 特定的应用程序在外模式描述的数据结构上编制的,依赖于特定的外模式,与数据库的模式和存储结构独立
- 不同的应用程序有时可以共用同一个外模式
数据库的二级映像
- 保证了数据库外模式的稳定性
- 从底层保证了应用程序的稳定性,除非应用需求本身发生变化,否则应用程序一般不需要修改
数据与程序之间的独立性
- 使得数据的定义和描述可以从应用程序中分离出去
- 数据的存取由数据库管理系统管理
- 简化了应用程序的编制
- 大大减少了应用程序的维护和修改
数据库系统的三级模式与二级映像的优点
(1)保证数据独立性。将模式和内模式分开,保证了数据的物理独立性;将外模式和模式分开,保证了数据的逻辑独立性。
(2)简化了用户接口。按照外模式编写应用程序或输入命令,而不需要了解数据库内部的存储结构,方便用户使用系统。
(3)有利于数据共享。在不同的外模式下可以有多个用户共享系统中数据,减少了数据冗余。
(4)有利于数据的安全保密。在外模式下根据需要进行操作,只能对限定的数据操作,保证了其他数据的安全。
第二章、关系型数据库
关系数据结构及形式化定义
关系
- 单一的数据结构----关系
- 现实世界的实体以及实体间的各种联系均用关系来表示
- 逻辑结构----二维表
- 从用户角度,关系模型中数据的逻辑结构是一张二维表
- 建立在集合代数的基础上
域(Domain)
- 域是一组具有相同数据类型的值的集合。例:
- 整数
- 实数
- 介于某个取值范围的整数
- 指定长度的字符串集合
- {‘男’,‘女’}
- ………………
笛卡尔积(Cartesian Product)
- 给定一组域 D1,D2,…,Dn,允许其中某些域是相同的。
- D1,D2,…,Dn 的笛卡尔积为:
[
D1 \times D2 \times … \times Dn = {(d1,d2,…,dn)|di \in Di,i=1,2,…,n}
] - 所有域的所有取值的一个组合
- 不能重复
- D1,D2,…,Dn 的笛卡尔积为:
元组(Tuple)
- 笛卡尔积中每一个元素(d1,d2,…,dn)叫作一个 n 元组(n-tuple)或简称元组
- (张清玫,计算机专业,李勇)
- (张清玫,计算机专业,刘晨)
分量(Component)
- 笛卡尔积元素(d1,d2,…,dn)中的每一个值 di 叫作一个分量
- 张清玫、计算机专业、李勇、刘晨等都是分量
基数(Cardinal number)
- 若 Di(i=1,2,…,n)为有限集,其基数为 mi(i=1,2,…,n),则 D1×D2×…×Dn 的基数 M 为:
[
M = m1 \times m2 \times … \times mn
]
笛卡尔积的表示方法
- 笛卡尔积可表示为一张二维表
- 表中的每行对应一个元组,表中的每列对应一个域
例如,给出 3 个域:
- D1 = 导师集合 SUPERVISOR = {张清玫,刘逸}
- D2 = 专业集合 SPECIALITY = {计算机专业,信息专业}
- D3 = 研究生集合 POSTGRADUATE = {李勇,刘晨,王敏}
D1,D2,D3 的笛卡尔积为:
[
D1 \times D2 \times D3 = \{
(张清玫,计算机专业,李勇),(张清玫,计算机专业,刘晨),(张清玫,计算机专业,王敏),
(张清玫,信息专业,李勇),(张清玫,信息专业,刘晨),(张清玫,信息专业,王敏),
(刘逸,计算机专业,李勇),(刘逸,计算机专业,刘晨),(刘逸,计算机专业,王敏),
(刘逸,信息专业,李勇),(刘逸,信息专业,刘晨),(刘逸,信息专业,王敏)
\}
]
基数为 2×2×3=12
关系(Relation)
-
关系
- D1×D2×…×Dn 的子集叫作在域 D1,D2,…,Dn 上的关系,表示为
[$
R(D1,D2,…,Dn)$
] - R:关系名
- n:关系的目或度(Degree)
- D1×D2×…×Dn 的子集叫作在域 D1,D2,…,Dn 上的关系,表示为
-
元组
- 关系中的每个元素是关系中的元组,通常用 t 表示。
-
单元关系与二元关系
- 当 n = 1 时,称该关系为单元关系(Unary relation)或一元关系
- 当 n = 2 时,称该关系为二元关系(Binary relation)
-
关系的表示
- 关系也是一个二维表,表的每行对应一个元组,表的每列对应一个域
-
属性
- 关系中不同列可以对应相同的域
- 为了加以区分,必须对每列起一个名字,称为属性(Attribute)
- n 目关系必有 n 个属性
-
码
- 候选码(Candidate key)
- 若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码
- 简单的情况:候选码只包含一个属性
- 全码(All-key)
- 最极端的情况:关系模式的所有属性组是这个关系模式的候选码,称为全码(All-key)
- 候选码(Candidate key)
-
主码
- 若一个关系有多个候选码,则选定其中一个为主码(Primary key)
- 主属性
- 候选码的诸属性称为主属性(Prime attribute)
- 不包含在任何候选码中的属性称为非主属性(Non-Prime attribute)或非码属性(Non-key attribute)
例如:
- D1,D2,…,Dn 的笛卡尔积的某个子集才有实际含义
- 表 2.1 的笛卡尔积没有实际意义
- 取出有实际意义的元组来构造关系
关系:SAP(SUPERVISOR,SPECIALITY,POSTGRADUATE)
- 假设:导师与专业:n: 1,导师与研究生:1: n
- 主码:POSTGRADUATE(假设研究生不会重名)
三类关系
-
基本关系(基本表或基表)
- 实际存在的表,是实际存储数据的逻辑表示
-
查询表
- 查询结果对应的表
-
视图表
- 由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据
基本关系的性质
-
列是同质的(Homogeneous)
-
不同的列可出自同一个域
- 其中的每一列称为一个属性
- 不同的属性要给予不同的属性名
-
列的顺序无所谓,列的次序可以任意交换
-
任意两个元组的候选码不能相同
-
行的顺序无所谓,行的次序可以任意交换
-
分量必须取原子值
-
这是规范条件中最基本的一条

-
关系模式
1. 什么是关系模式
- 关系模式(Relation Schema) 是型,关系是值
- 关系模式是对关系的描述,包括:
- 元组集合的结构
- 属性构成
- 属性来自的域
- 属性与域之间的映象关系
- 完整性约束条件
- 元组集合的结构
2. 定义关系模式
- 关系模式可以形式化地表示为:
[
R(U,D,DOM,F)
]- R: 关系名
- U: 组成该关系的属性名集合
- D: U 中属性所来自的域
- DOM: 属性向域的映象集合
- F: 属性间数据的依赖关系的集合
例:
-
导师和研究生出自同一个域——人,取不同的属性名,并在模式中定义属性向域的映象,即说明它们分别出自哪个域:
[
DOM(SUPERVISOR-PERSON) = DOM(POSTGRADUATE-PERSON) = PERSON
] -
关系模式通常可以简记为:
[
R (U) 或 R (A1,A2,…,An)
]- R: 关系名
- A1,A2,…,An: 属性名
- 注:域名及属性向域的映象常常直接说明为属性的类型、长度
3. 关系模式与关系
-
关系模式
- 对关系的描述
- 静态的、稳定的
-
关系
- 关系模式在某一时刻的状态或内容
- 动态的、随时间不断变化的
-
关系模式和关系往往笼统称为关系,通过上下文加以区别
关系数据库
-
关系数据库:
- 在一个给定的应用领域中,所有关系的集合构成一个关系数据库。
-
关系数据库的型与值:
- 关系数据库的型:
- 关系数据库模式,是对关系数据库的描述。
- 关系数据库的值:
- 关系模式在某一时刻对应的关系的集合,通常称为关系数据库。
- 关系数据库的型:
关系模型的存储结构
- 关系数据库的物理组织:
- 在一些关系数据库管理系统中,一个表对应一个操作系统文件,将物理数据组织交给操作系统完成。
- 在其他关系数据库管理系统中,从操作系统那里申请若干个大的文件,自己划分文件空间,组织表、索引等存储结构,并进行存储管理。
关系操作
基本关系操作
-
常用的关系操作:
- 查询操作:
- 选择(Select)
- 投影(Project)
- 连接(Join)
- 除(Divide)
- 并(Union)
- 差(Difference)
- 交(Intersection)
- 笛卡尔积(Cartesian Product)
- 基本操作:
- 选择
- 投影
- 并
- 差
- 笛卡尔积
- 数据更新:
- 插入(Insert)
- 删除(Delete)
- 修改(Update)
- 查询操作:
-
关系操作的特点:
- 集合操作方式:
- 操作的对象和结果都是集合,一次一集合的方式
- 集合操作方式:
关系数据库语言的分类
-
关系代数语言:
- 用对关系的运算来表达查询要求
- 代表:ISBL
-
关系演算语言:
-
用谓词来表达查询要求
-
元组关系演算语言:
- 谓词变元的基本对象是元组变量
- 代表:APLHA, QUEL
-
域关系演算语言:
- 谓词变元的基本对象是域变量
- 代表:QBE
-
-
具有关系代数和关系演算双重特点的语言:
- 代表:SQL(Structured Query Language)
关系的完整性( 重点 )
关系模型必须满足的完整性约束条件称为关系的三个不变性:
- 实体完整性
- 参照完整性
- 用户定义的完整性
实体完整性
规则 2.1 实体完整性规则(Entity Integrity)
- 若属性 A 是基本关系 R 的主属性,则属性 A 不能取空值。
- 空值表示“不知道”或“不存在”或“无意义”的值。
例子: 选修(学号,课程号,成绩)
主码:学号、课程号
说明:学号和课程号都不能取空值。
实体完整性规则的说明:
- 实体完整性规则是针对基本关系而言的。
- 基本表通常对应现实世界的一个实体集。
- 现实世界中的实体具有唯一性标识。
- 关系模型中以主码作为唯一性标识。
- 主码中的属性即主属性不能取空值。
- 主属性取空值,意味着存在某个不可标识的实体,这与唯一性标识的要求相矛盾,因此这个规则称为实体完整性。
参照完整性
1. 关系间的引用
- 在关系模型中,实体及实体间的联系都是用关系来描述的,存在关系与关系间的引用。
例 2.1 学生实体、专业实体
学生(学号,姓名,性别,专业号,年龄)
专业(专业号,专业名)
说明:学生关系引用了专业关系的主码“专业号”,学生关系中的“专业号”值必须是确实存在的专业的专业号。
例 2.2 学生、课程、学生与课程之间的多对多联系
学生(学号,姓名,性别,专业号,年龄)
课程(课程号,课程名,学分)
选修(学号,课程号,成绩)
例 2.3 学生实体及其内部的一对多联系
学生(学号,姓名,性别,专业号,年龄,班长)
数据示例:
| 学号 | 姓名 | 性别 | 专业号 | 年龄 | 班长 |
|---|---|---|---|---|---|
| 801 | 张三 | 女 | 01 | 19 | 802 |
| 802 | 李四 | 男 | 01 | 20 | |
| 803 | 王五 | 男 | 01 | 20 | 802 |
| 804 | 赵六 | 女 | 02 | 20 | 805 |
| 805 | 钱七 | 男 | 02 | 19 |
说明:“学号”是主码,“班长”是外码,它引用了本关系的“学号”,“班长”必须是确实存在的学生的学号。
2. 外码(Foreign Key)
- 设 F 是基本关系 R 的一个或一组属性,但不是关系 R 的码。如果 F 与基本关系 S 的主码 Ks 相对应,则称 F 是 R 的外码。
- 基本关系 R 称为参照关系(Referencing Relation)。
- 基本关系 S 称为被参照关系(Referenced Relation)或目标关系(Target Relation)。
例 2.1 学生关系的“专业号”与专业关系的主码“专业号”相对应。
说明:“专业号”是学生关系的外码,专业关系是被参照关系,学生关系为参照关系。

例 2.2 选修关系的“学号”与学生关系的主码“学号”相对应,选修关系的“课程号”与课程关系的主码“课程号”相对应。
说明:“学号”和“课程号”是选修关系的外码,学生关系和课程关系均为被参照关系,选修关系为参照关系。
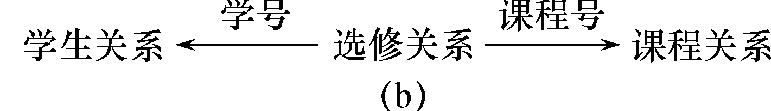
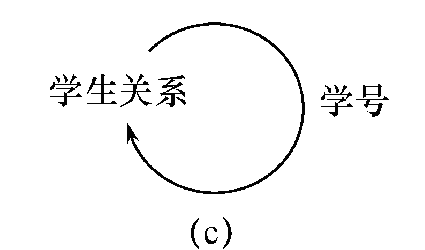
例 2.3 “班长”与本身的主码“学号”相对应。
说明:“班长”是外码,学生关系既是参照关系也是被参照关系。
- 关系 R 和 S 不一定是不同的关系。
- 目标关系 S 的主码 Ks 和参照关系的外码 F 必须定义在同一个(或一组)域上。
- 外码并不一定要与相应的主码同名。
- 当外码与相应的主码属于不同关系时,往往取相同的名字,以便于识别。
3. 参照完整性规则
规则 2.2 参照完整性规则
- 若属性(或属性组)F 是基本关系 R 的外码,它与基本关系 S 的主码 Ks 相对应(基本关系 R 和 S 不一定是不同的关系),则对于 R 中每个元组在 F 上的值必须为:
- 空值(F 的每个属性值均为空值)
- 或者等于 S 中某个元组的主码值
例 2.1 学生关系中每个元组的“专业号”属性只取两类值:
- 空值,表示尚未给该学生分配专业。
- 非空值,必须是专业关系中某个元组的“专业号”值。
例 2.2 选修(学号,课程号,成绩)
- 主属性不能取空值。
- 只能取相应被参照关系中已存在的主码值。
例 2.3 学生(学号,姓名,性别,专业号,年龄,班长)
- 班长属性值可以取两类值:
- 空值,表示该学生所在班级尚未选出班长。
- 非空值,必须是本关系中某个元组的学号值。
用户定义的完整性
- 针对某一具体关系数据库的约束条件,反映具体应用所涉及的数据必须满足的语义要求。
- 关系模型应提供定义和检验这类完整性的机制,以便用统一的系统的方法处理,而不需由应用程序承担这一功能。
例子: 课程(课程号,课程名,学分)
- “课程号”属性必须取唯一值。
- 非主属性“课程名”不能取空值。
- “学分”属性只能取值{1,2,3,4}。
第三章、关系数据库标准语言 SQL
SQL 概述( 了解 )
SQL(Structured Query Language) 是关系数据库的标准语言,是一个通用的、功能极强的关系数据库语言。
SQL 的产生与发展
SQL 语言最早于 1970 年代在 IBM 公司的 San Jose 研究实验室被开发,后来成为关系数据库的标准语言。
SQL 的特点
-
综合统一:
- 集数据定义语言(DDL)、数据操纵语言(DML)、数据控制语言(DCL)功能于一体。
- 独立完成数据库生命周期中的全部活动:定义和修改、删除关系模式,定义和删除视图,插入数据,建立数据库。
- 对数据库中的数据进行查询和更新。
- 数据库重构和维护,安全性、完整性控制,以及事务控制。
- 支持嵌入式 SQL 和动态 SQL 定义。
-
高度非过程化:
- SQL 语言只需提出“做什么”,而不必了解存取路径,存取路径的选择及 SQL 的操作过程由系统自动完成。
-
面向集合的操作方式:
- 操作对象可以是元组的集合,一次插入、删除、更新操作的对象可以是元组的集合。
-
多种使用方式:
- SQL 是独立的语言,能够独立地用于联机交互。
- SQL 又是嵌入式语言,能够嵌入到高级语言(例如 C,C++,Java)程序中,供程序员设计程序时使用。
-
语言简洁,易学易用:
- SQL 功能极强,完成核心功能只用了 9 个动词。
| SQL 功能 | 动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE, DROP, ALTER |
| 数据操纵 | INSERT, UPDATE, DELETE |
| 数据控制 | GRANT, REVOKE |
SQL 的基本概念
SQL 支持关系数据库三级模式结构:
graph TD;
SQL[SQL]
subgraph 外模式
视图1[视图1]
视图2[视图2]
end
subgraph 模式
基本表1[基本表1]
基本表2[基本表2]
基本表3[基本表3]
基本表4[基本表4]
end
subgraph 内模式
存储文件1[存储文件1]
存储文件2[存储文件2]
end
SQL --> 视图1
SQL --> 视图2
SQL --> 基本表1
视图1 --> 基本表2
视图2 --> 基本表3
视图2 --> 基本表4
基本表1 --> 存储文件1
基本表2 --> 存储文件1
基本表3 --> 存储文件1
基本表4 --> 存储文件2
基本表:
- 本身独立存在的表。
- SQL 中一个关系就对应一个基本表
- 一个(或多个)基本表对应一个存储文件。
- 一个表可以带若干索引
存储文件:
- 逻辑结构组成了关系数据库的内模式
- 物理结构对用户是隐蔽的。
视图:
- 从一个或几个基本表导出的表
- 数据库中只存放视图的定义而不存放视图对应的数据
- 视图是一个虚表
- 用户可以在视图上再定义视图。
学生-课程数据库(看一遍怎么创建)
学生-课程模式 S-T :
- 学生表:Student(Sno, Sname, Ssex, Sage, Sdept)
- 课程表:Course(Cno, Cname, Cpno, Ccredit)
- 学生选课表:SC(Sno, Cno, Grade)
Student 表:
| Sno | Sname | Ssex | Sage | Sdept |
|---|---|---|---|---|
| 201215121 | 李勇 | 男 | 20 | CS |
| 201215122 | 刘晨 | 女 | 19 | CS |
| 201215123 | 王敏 | 女 | 18 | MA |
| 201215125 | 张立 | 男 | 19 | IS |
Course 表:
| Cno | Cname | Cpno | Ccredit |
|---|---|---|---|
| 1 | 数据库 | 5 | 4 |
| 2 | 数学 | 2 | |
| 3 | 信息系统 | 1 | 4 |
| 4 | 操作系统 | 6 | 3 |
| 5 | 数据结构 | 7 | 4 |
| 6 | 数据处理 | 2 | |
| 7 | PASCAL 语言 | 6 | 4 |
SC 表:
| Sno | Cno | Grade |
|---|---|---|
| 201215121 | 1 | 92 |
| 201215121 | 2 | 85 |
| 201215121 | 3 | 88 |
| 201215122 | 2 | 90 |
| 201215122 | 3 | 80 |
数据类型:
| 数据类型 | 含义 |
|---|---|
| CHAR(n), CHARACTER(n) | 长度为 n 的定长字符串 |
| VARCHAR(n), CHARACTER VARYING(n) | 最大长度为 n 的变长字符串 |
| CLOB | 字符串大对象 |
| BLOB | 二进制大对象 |
| INT, INTEGER | 长整数(4 字节) |
| SMALLINT | 短整数(2 字节) |
| BIGINT | 大整数(8 字节) |
| NUMERIC(p, d), DECIMAL(p, d) | 定点数,p 位数字,d 位小数 |
| REAL | 单精度浮点数,机器精度 |
| DOUBLE PRECISION | 双精度浮点数,机器精度 |
| FLOAT(n) | 可选精度的浮点数,至少 n 位数字 |
| BOOLEAN | 逻辑布尔量 |
| DATE | 日期,格式为 YYYY-MM-DD |
| TIME | 时间,格式为 HH: MM: SS |
| TIMESTAMP | 时间戳类型 |
| INTERVAL | 时间间隔类型 | |
数据定义
数据字典:
- 数据字典是关系数据库管理系统内部的一组系统表,它记录了数据库中所有定义信息:
- 关系模式定义
- 视图定义
- 索引定义
- 完整性约束定义
- 各类用户对数据库的操作权限
- 统计信息等
- 关系数据库管理系统在执行 SQL 的数据定义语句时,实际上就是在更新数据字典表中的相应信息。
SQL 的数据定义功能:
- 模式定义
- 表定义
- 视图和索引的定义
表 3.3 SQL 的数据定义语句:
| 操作对象 | 操作方式 | ||
|---|---|---|---|
| 创建 | 删除 | 修改 | |
| 模式 | CREATE SCHEMA | DROP SCHEMA | |
| 表 | CREATE TABLE | DROP TABLE | ALTER TABLE |
| 视图 | CREATE VIEW | DROP VIEW | |
| 索引 | CREATE INDEX | DROP INDEX | ALTER INDEX |
模式的定义与删除
graph TD;
数据库["数据库(有的系统称为目录)"];
模式["模式"];
表["表以及视图、索引等"];
数据库 ---> 模式;
模式 ---> 表;
现代关系数据库管理系统提供了一个层次化的数据库对象命名机制
- 一个关系数据库管理系统的实例(Instance)中可以建立多个数据库。
- 一个数据库中可以建立多个模式。
- 一个模式下通常包括多个表、视图和索引等数据库对象。
-
定义模式
CREATE SCHEMA “S-T” AUTHORIZATION WANG; CREATE SCHEMA AUTHORIZATION WANG;例 3.3 为用户 ZHANG 创建了一个模式 TEST,并且在其中定义一个表 TAB1:
CREATE SCHEMA TEST AUTHORIZATION ZHANG CREATE TABLE TAB1 ( COL1 SMALLINT, COL2 INT, COL3 CHAR(20), COL4 NUMERIC(10,3), COL5 DECIMAL(5,2) ); -
删除模式
DROP SCHEMA <模式名> <CASCADE|RESTRICT>;
基本表的定义、删除与修改
- 定义基本表:
```sql
CREATE TABLE <表名> (
<列名> <数据类型> [<列级完整性约束条件>],
...
[<表级完整性约束条件>]
);
```
- 例 3.5 建立“学生”表 Student。学号是主码,姓名取值唯一:
```sql
CREATE TABLE Student (
Sno CHAR(9) PRIMARY KEY,
Sname CHAR(20) UNIQUE,
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
```
- 例 3.6 建立一个“课程”表 Course:
```sql
CREATE TABLE Course (
Cno CHAR(4) PRIMARY KEY,
Cname CHAR(40),
Cpno CHAR(4),
Ccredit SMALLINT,
FOREIGN KEY (Cpno) REFERENCES Course(Cno)
);
```
- 例 3.7 建立一个学生选课表 SC:
```sql
CREATE TABLE SC (
Sno CHAR(9),
Cno CHAR(4),
Grade SMALLINT,
PRIMARY KEY (Sno, Cno),
FOREIGN KEY (Sno) REFERENCES Student(Sno),
FOREIGN KEY (Cno) REFERENCES Course(Cno)
);
```
-
修改基本表
ALTER TABLE <表名> [ADD [COLUMN] <新列名> <数据类型> [完整性约束]] [ADD <表级完整性约束>] [DROP [COLUMN] <列名> [CASCADE|RESTRICT]] [DROP CONSTRAINT <完整性约束名> [RESTRICT | CASCADE]] [ALTER COLUMN <列名> <数据类型>];-
例 3.8 向 Student 表增加“入学时间”列:
ALTER TABLE Student ADD S_entrance DATE; -
例 3.9 将年龄的数据类型由字符型改为整数:
ALTER TABLE Student ALTER COLUMN Sage INT; -
例 3.10 增加课程名称必须取唯一值的约束条件:
ALTER TABLE Course ADD UNIQUE(Cname);
-
-
删除基本表
DROP TABLE <表名> <CASCADE|RESTRICT>;- 例 3.11 删除“学生”表:
DROP TABLE Student CASCADE;
- 例 3.11 删除“学生”表:
索引定义和删除
在 SQL 中,索引是一种优化数据库表格查询性能的重要工具。它类似于书籍的目录,可以加快在数据库表中查找特定数据的速度。索引可以单独或者组合多列来创建,有时还可以定义为唯一索引,这意味着索引列的值在整个表中必须是唯一的。
创建索引
在 SQL 中,使用 CREATE INDEX 语句来创建索引,语法通常如下:
CREATE [UNIQUE] INDEX <索引名>
ON <表名>(<列名> [ASC|DESC] [,...]);
UNIQUE关键字是可选的,如果指定了,将创建一个唯一索引,确保索引列中的所有值都是唯一的。<索引名>是你为索引指定的名称,用于标识这个索引。<表名>是要在其上创建索引的表的名称。<列名>是要包含在索引中的列的名称。你可以指定一个或多个列,以逗号分隔。每个列都可以指定是升序(ASC,默认)还是降序(DESC)。
例如,为学生表 Student 的 Sname 列创建一个普通索引可以这样做:
CREATE INDEX StuName_Index ON Student(Sname);
这将在 Student 表的 Sname 列上创建一个名为 StuName_Index 的普通索引,用于加快按照学生姓名进行查询的速度。
删除索引
如果不再需要某个索引或者要重新设计索引,可以使用 DROP INDEX 语句来删除索引。语法如下:
DROP INDEX <索引名>;
<索引名>是要删除的索引的名称。
例如,如果要删除上述创建的 StuName_Index 索引,可以执行以下语句:
DROP INDEX StuName_Index;
这将从数据库中删除 StuName_Index 索引,不再使用它来加速对 Student 表中 Sname 列的查询操作。
数据查询 (重点大题)
数据查询是数据库语言的重要功能之一。SQL 提供了强大的查询功能,使用户能方便地从数据库中获取所需数据。
-
SELECT 语句的基本形式:
SELECT <目标列表> FROM <表名或视图名> [,...] [WHERE <条件表达式>] [GROUP BY <列名>[HAVING <条件表达式>]] [ORDER BY <列名>[ASC|DESC][,...]]; -
查询实例( 重点掌握 )
-
例 3.14 查询学生表 Student 中所有记录的学号、姓名和系:
SELECT Sno, Sname, Sdept FROM Student; -
例 3.15 查询学生表中年龄在 20 岁以上的学生的学号和姓名:
SELECT Sno, Sname FROM Student WHERE Sage > 20; -
例 3.16 查询选修了数据库课程的所有学生的学号:
SELECT Sno FROM SC WHERE Cno = '1'; -
例 3.17 查询每门课程的平均成绩:
SELECT Cno, AVG(Grade) FROM SC GROUP BY Cno; -
例 3.18 查询选修数据库课程且成绩在 85 分以上的学生学号及其姓名:
SELECT Sno, Sname FROM Student WHERE Sno IN (SELECT Sno FROM SC WHERE Cno = '1' AND Grade > 85);
-
-
连接查询
-
例 3.19 查询每位学生选修的课程及其成绩:
SELECT Student.Sno, Student.Sname, SC.Cno, SC.Grade FROM Student, SC WHERE Student.Sno = SC.Sno; -
例 3.20 查询选修了数据库课程的学生姓名和成绩:
SELECT Student.Sname, SC.Grade FROM Student JOIN SC ON Student.Sno = SC.Sno WHERE SC.Cno = '1';
-
-
嵌套查询
- 例 3.21 查询选修了与 201215121 学生同样课程的学生学号:
SELECT DISTINCT Sno FROM SC WHERE Cno IN (SELECT Cno FROM SC WHERE Sno = '201215121') AND Sno <> '201215121';
- 例 3.21 查询选修了与 201215121 学生同样课程的学生学号:
-
集合查询( 没考到 )
-
例 3.22 查询选修了数据库课程或数学课程的学生学号:
SELECT Sno FROM SC WHERE Cno = '1' UNION SELECT Sno FROM SC WHERE Cno = '2'; -
例 3.23 查询既选修了数据库课程又选修了数学课程的学生学号:
SELECT Sno FROM SC WHERE Cno = '1' INTERSECT SELECT Sno FROM SC WHERE Cno = '2'; -
例 3.24 查询选修了数据库课程但没有选修数学课程的学生学号:
SELECT Sno FROM SC WHERE Cno = '1' EXCEPT SELECT Sno FROM SC WHERE Cno = '2';
-
-
子查询(Subquery)
子查询与嵌套查询类似,但子查询可以出现在 SELECT、FROM 和 WHERE 子句中。示例如下:
在 SELECT 子句中使用子查询:
SELECT employee_id, (SELECT department_name FROM departments WHERE departments.department_id = employees.department_id) AS department_name FROM employees;在 FROM 子句中使用子查询:
SELECT e.first_name, e.last_name, d.department_name FROM employees e, (SELECT department_id, department_name FROM departments) d WHERE e.department_id = d.department_id;在 WHERE 子句中使用子查询:
SELECT first_name, last_name FROM employees WHERE salary > (SELECT AVG(salary) FROM employees); -
INNER JOIN
INNER JOIN 用于返回两个表中共有的记录。示例如下:
SELECT employees.first_name, employees.last_name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id; -
LEFT JOIN
LEFT JOIN 用于返回左表中的所有记录以及右表中匹配的记录,如果没有匹配则返回 NULL。示例如下:
SELECT employees.first_name, employees.last_name, departments.department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.department_id; -
查询方式的不同总结
- 普通查询:简单地从单个表中选择数据。
- 嵌套查询:在一个查询中嵌套另一个查询,用于复杂的条件查询。
- 子查询:在 SELECT、FROM 或 WHERE 子句中使用查询结果。
- INNER JOIN:返回两个表中共有的记录。
- LEFT JOIN:返回左表中的所有记录及右表中匹配的记录,若没有匹配则返回 NULL。
我们可以使用 Mermaid 图来可视化 INNER JOIN 和 LEFT JOIN 的概念。
INNER JOIN
erDiagram
EMPLOYEES {
int employee_id
string first_name
string last_name
int department_id
}
DEPARTMENTS {
int department_id
string department_name
}
EMPLOYEES ||--|| DEPARTMENTS: "department_id"
LEFT JOIN
erDiagram
EMPLOYEES {
int employee_id
string first_name
string last_name
int department_id
}
DEPARTMENTS {
int department_id
string department_name
}
EMPLOYEES }|--|| DEPARTMENTS: "department_id"
假设有两个集合 A 和 B:
- INNER JOIN 的结果是 A \cap B(交集)。
- LEFT JOIN 的结果是 A \cup (B \cap A)(左集合的全部,加上交集)。
数据更新
SQL 的数据操纵功能包括插入、更新和删除操作。
-
插入操作
INSERT INTO <表名> [(<列名>[,...])] VALUES (<值表达式>[,...]);- 例 3.25 向学生表插入一条记录:
INSERT INTO Student (Sno, Sname, Ssex, Sage, Sdept) VALUES ('201215124', '陈刚', '男', 18, 'IS');
- 例 3.25 向学生表插入一条记录:
-
更新操作
UPDATE <表名> SET <列名>=<值表达式>[,...] [WHERE <条件表达式>];- 例 3.26 将学生表中所有“IS”专业的学生年龄加 1:
UPDATE Student SET Sage = Sage + 1 WHERE Sdept = 'IS';
- 例 3.26 将学生表中所有“IS”专业的学生年龄加 1:
-
删除操作
DELETE FROM <表名> [WHERE <条件表达式>];- 例 3.27 删除学生表中所有选修数据库课程的学生记录:
DELETE FROM Student WHERE Sno IN (SELECT Sno FROM SC WHERE Cno = '1');
- 例 3.27 删除学生表中所有选修数据库课程的学生记录:
空值处理
在 SQL 中,空值(NULL)表示缺失、不确定或未知的值。处理空值是数据库操作中的一个重要部分,因为它会影响查询结果、计算和逻辑判断。以下是关于空值处理的详细讲解:
空值的产生
空值通常在以下情况下产生:
- 插入数据时未指定某些列的值。
- 数据更新时将列值设置为 NULL。
- 计算或操作结果为 NULL。
示例:
-- 插入数据时未指定某些列的值
INSERT INTO Students (Sno, Sname) VALUES ('001', 'Alice');
-- 数据更新时将列值设置为NULL
UPDATE Students SET Sclass = NULL WHERE Sno = '001';
空值的判断
使用 IS NULL 或 IS NOT NULL 来判断某列是否为空值。
示例:
-- 查找Sclass列为空值的学生
SELECT Sno, Sname FROM Students WHERE Sclass IS NULL;
-- 查找Sclass列不为空值的学生
SELECT Sno, Sname FROM Students WHERE Sclass IS NOT NULL;
空值的约束条件
在创建或修改表时,可以使用 NOT NULL 约束来防止列出现空值。
示例:
-- 创建表时添加NOT NULL约束
CREATE TABLE Students (
Sno VARCHAR(10) PRIMARY KEY,
Sname VARCHAR(50) NOT NULL,
Sclass VARCHAR(10) NOT NULL
);
-- 修改表时添加NOT NULL约束
ALTER TABLE Students MODIFY Sclass VARCHAR(10) NOT NULL;
空值的处理
处理空值可以使用 COALESCE 函数或 IFNULL 函数(在某些数据库系统中)。
示例:
-- 使用COALESCE函数处理空值,返回第一个非空值
SELECT Sno, COALESCE(Sclass, 'Unknown') AS Class FROM Students;
-- 使用IFNULL函数处理空值(MySQL)
SELECT Sno, IFNULL(Sclass, 'Unknown') AS Class FROM Students;
空值的算术运算
算术运算中如果操作数包含 NULL,结果通常为 NULL。
示例:
-- 假设某些学生的分数为NULL
SELECT Sno, Score + 10 AS NewScore FROM Students;
-- 结果中Score为NULL的行,NewScore也为NULL
空值的比较运算
比较运算中如果操作数包含 NULL,结果通常为 UNKNOWN(即不确定)。
示例:
-- 比较运算中包含NULL的情况
SELECT Sno FROM Students WHERE Score > 80;
-- 结果中Score为NULL的行不会被选中,因为NULL > 80结果为UNKNOWN
空值的逻辑运算
逻辑运算(AND、OR、NOT)中如果操作数包含 NULL,结果可能为 TRUE、FALSE 或 UNKNOWN。
逻辑与(AND)
- 如果一个操作数为 FALSE,结果为 FALSE。
- 如果所有操作数为 TRUE,结果为 TRUE。
- 其他情况结果为 UNKNOWN。
示例:
SELECT Sno FROM Students WHERE (Score > 80) AND (Sclass IS NOT NULL);
-- 如果Score为NULL或Sclass为NULL,结果为UNKNOWN,不会被选中
逻辑或(OR)
- 如果一个操作数为 TRUE,结果为 TRUE。
- 如果所有操作数为 FALSE,结果为 FALSE。
- 其他情况结果为 UNKNOWN。
示例:
SELECT Sno FROM Students WHERE (Score > 80) OR (Sclass IS NULL);
-- 如果Score为NULL且Sclass为NULL,结果为UNKNOWN,不会被选中
逻辑非(NOT)
- 如果操作数为 TRUE,结果为 FALSE。
- 如果操作数为 FALSE,结果为 TRUE。
- 如果操作数为 UNKNOWN,结果为 UNKNOWN。
示例:
SELECT Sno FROM Students WHERE NOT (Sclass IS NULL);
-- 如果Sclass为NULL,结果为UNKNOWN,不会被选中
总结
处理空值在数据库操作中非常重要,以下是一些关键点:
- 空值的产生:未指定值或显式设置为 NULL。
- 空值的判断:使用
IS NULL或IS NOT NULL。 - 空值的约束条件:使用
NOT NULL约束防止空值。 - 空值的处理:使用
COALESCE或IFNULL函数替换空值。 - 空值的算术运算:包含空值的结果通常为 NULL。
- 空值的比较运算:包含空值的结果通常为 UNKNOWN。
- 空值的逻辑运算:包含空值的结果可能为 TRUE、FALSE 或 UNKNOWN。
视图( 重点:定义和操作 )
视图(View)是 SQL 中的一种虚拟表,它由一个查询定义,并存储在数据库中。视图的内容是动态的,每次访问视图时,数据库系统会根据视图的定义查询相应的数据。视图的作用包括简化复杂查询、提高安全性和数据抽象。以下是视图的定义、删除和修改方法的详细解释:
视图的作用主要包括以下几个方面:
视图的作用( 重点 )
简化复杂查询
简化复杂查询
- 预定义复杂查询:视图可以将复杂的 SQL 查询封装起来,用户只需简单地查询视图即可得到结果,无需重复编写复杂的 SQL 语句。例如,将多个表的连接查询、聚合查询等复杂操作封装在视图中。
- 提高可读性和维护性:通过使用视图,可以将复杂的查询逻辑隐藏起来,使 SQL 代码更简洁和易读,有助于提高代码的可维护性。
-- 定义一个复杂查询的视图
CREATE VIEW EmployeeSales AS
SELECT e.EmployeeID, e.FirstName, e.LastName, SUM(o.TotalAmount) AS TotalSales
FROM Employees e
JOIN Orders o ON e.EmployeeID = o.EmployeeID
GROUP BY e.EmployeeID, e.FirstName, e.LastName;
2. 提高安全性
提高安全性
- 限制数据访问:视图可以用于限制用户访问敏感数据。例如,可以创建只包含非敏感数据的视图,让用户通过视图访问数据,而不能直接访问底层表,从而保护敏感信息。
- 基于权限的访问控制:可以为视图分配不同的访问权限,控制哪些用户可以查看、插入、更新或删除视图中的数据,而无需修改底层表的权限。
-- 创建一个不包含敏感信息的视图
CREATE VIEW PublicEmployeeInfo AS
SELECT EmployeeID, FirstName, LastName, Department
FROM Employees;
-- 为特定用户授予访问视图的权限
GRANT SELECT ON PublicEmployeeInfo TO PublicUser;
3. 数据抽象
数据抽象
- 隐藏底层表结构:视图可以隐藏数据库的复杂结构和变化,提供一个稳定的接口给用户,即使底层表结构发生变化,只需修改视图定义即可,用户的查询不会受到影响。
- 数据转换和格式化:视图可以用于数据转换和格式化,如计算字段、重命名列、数据过滤等,使用户看到的数据更加符合业务需求。
-- 创建一个视图来格式化和转换数据
CREATE VIEW FormattedEmployeeInfo AS
SELECT EmployeeID, CONCAT(FirstName, ' ', LastName) AS FullName,
FORMAT(HireDate, 'yyyy-MM-dd') AS HireDateFormatted
FROM Employees;
4. 数据隔离
数据隔离
- 分离操作数据和分析数据:视图可以用于分离操作数据和分析数据。例如,创建专门用于报表和分析的视图,使操作数据与分析数据分开,减少对操作数据库的影响。
- 提供不同的视角:通过创建不同的视图,可以为不同的用户群体提供定制的数据视图,满足不同的业务需求。
-- 创建一个用于分析的视图
CREATE VIEW SalesAnalysis AS
SELECT ProductID, SUM(Quantity) AS TotalQuantity, SUM(TotalAmount) AS TotalSales
FROM OrderDetails
GROUP BY ProductID;
5. 数据集成
数据集成
- 合并多源数据:视图可以用于整合来自多个表或多个数据库的数据,提供一个统一的视图,方便用户进行数据访问和分析。
- 简化数据访问:通过视图可以简化对分布在不同表中的数据的访问,用户无需关心数据的存储细节。
-- 创建一个跨多个表的视图
CREATE VIEW CustomerOrderSummary AS
SELECT c.CustomerID, c.CustomerName, o.OrderID, o.OrderDate, o.TotalAmount
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID;
- 合并多源数据:视图可以用于整合来自多个表或多个数据库的数据,提供一个统一的视图,方便用户进行数据访问和分析。
- 简化数据访问:通过视图可以简化对分布在不同表中的数据的访问,用户无需关心数据的存储细节。
-- 创建一个跨多个表的视图
CREATE VIEW CustomerOrderSummary AS
SELECT c.CustomerID, c.CustomerName, o.OrderID, o.OrderDate, o.TotalAmount
FROM Customers c
JOIN Orders o ON c.CustomerID = o.CustomerID;
视图定义
定义视图的基本语法如下:
CREATE VIEW <视图名> [(<列名>[,...])]
AS <子查询>
[WITH [CASCADE|LOCAL] CHECK OPTION];
例子
假设我们有一个 Student 表和一个 SC 表:
-
Student表包含学生信息:Sno:学号Sname:姓名- 其他字段…
-
SC表包含学生选课信息:Sno:学号Cno:课程号- 其他字段…
我们要建立一个视图,使其包含选修了数据库课程的学生学号及其姓名。
CREATE VIEW S_V1 AS
SELECT Sno, Sname
FROM Student
WHERE Sno IN
(SELECT Sno FROM SC WHERE Cno = '1');
这个视图 S_V1 包含了所有选修了课程号为 1(假设为数据库课程)的学生的学号和姓名。
删除视图
删除视图的基本语法如下:
DROP VIEW <视图名> [RESTRICT|CASCADE];
RESTRICT:如果其他对象依赖于该视图,则不允许删除视图。CASCADE:如果其他对象依赖于该视图,删除视图的同时也删除所有依赖于该视图的对象。
例子
要删除之前创建的视图 S_V1:
DROP VIEW S_V1;
如果使用 CASCADE 选项:
DROP VIEW S_V1 CASCADE;
修改视图
标准 SQL 不支持直接修改视图。如果需要修改视图的定义,通常的做法是先删除视图,然后重新创建视图。
例子
假设我们要修改视图 S_V1,使其包含选修了数据库课程的学生学号、姓名及其所在的班级 Sclass。我们需要先删除视图,然后重新创建视图:
- 删除原视图:
DROP VIEW S_V1;
- 重新创建视图:
CREATE VIEW S_V1 AS
SELECT Sno, Sname, Sclass
FROM Student
WHERE Sno IN
(SELECT Sno FROM SC WHERE Cno = '1');
总结
- 定义视图:使用
CREATE VIEW语句,基于一个子查询定义视图。 - 删除视图:使用
DROP VIEW语句,可以选择RESTRICT或CASCADE选项。 - 修改视图:标准 SQL 不支持直接修改视图,通常通过删除和重新创建视图来实现修改。
视图在数据库管理中起到重要作用,通过视图可以简化查询、保护数据安全以及提供数据的不同视图。这些操作有助于更好地管理和使用数据库中的数据。
数据控制
SQL 的数据控制功能包括定义和管理数据库的安全性、完整性以及并发控制等。
-
定义权限
GRANT <权限>[,...] ON <对象类型><对象名>[,...] TO <用户>[,...] [WITH GRANT OPTION];- 例 3.28 授予用户 U1 对学生表的查询权限:
GRANT SELECT ON Student TO U1;
- 例 3.28 授予用户 U1 对学生表的查询权限:
-
撤销权限
REVOKE <权限>[,...] ON <对象类型><对象名>[,...] FROM <用户>[,...];- 例 3.29 撤销用户 U1 对学生表的查询权限:
REVOKE SELECT ON Student FROM U1;
- 例 3.29 撤销用户 U1 对学生表的查询权限:
-
事务控制
-
开始事务:
BEGIN TRANSACTION; -
提交事务:
COMMIT; -
回滚事务:
ROLLBACK;
-
视图与索引
视图和索引是关系数据库的重要功能,视图提供了数据的逻辑表示,索引提供了数据的快速访问途径。
-
定义视图
CREATE VIEW <视图名> [(<列名>[,...])] AS <子查询> [WITH [CASCADE|LOCAL] CHECK OPTION]; -
定义索引
CREATE [UNIQUE] INDEX <索引名> ON <表名>(<列名> [ASC|DESC] [,...]); -
使用视图和索引的查询
-
视图的查询:
SELECT <目标列表> FROM <视图名> [WHERE <条件表达式>] [ORDER BY <列名>[ASC|DESC]]; -
索引的查询:
SELECT <目标列表> FROM <表名> [WHERE <条件表达式>] [ORDER BY <列名>[ASC|DESC]];
-
小结
SQL 是关系数据库的标准语言,具有综合统一、高度非过程化、面向集合的操作方式、多种使用方式以及语言简洁等特点。SQL 的主要功能包括数据定义、数据查询、数据操纵、数据控制、视图与索引的定义等。在学习和使用 SQL 时,需要掌握其语法规则和操作方式,以便在实际应用中灵活运用。
第四章、数据库安全性
问题的提出
- 数据库的一大特点是数据可以共享
- 数据共享必然带来数据库的安全性问题
- 数据库系统中的数据共享不能是无条件的共享
- 例: 军事秘密、国家机密、新产品实验数据、
- 市场需求分析、市场营销策略、销售计划、
- 客户档案、医疗档案、银行储蓄数据
数据库的安全性是指保护数据库以防止不合法使用所造成的数据泄露、更改或破坏 。
系统安全保护措施是否有效是数据库系统主要的性能指标之一。
数据库安全性概述( 了解 )
4.1.1 数据库的不安全因素
-
非授权用户对数据库的恶意存取和破坏
- 一些黑客(Hacker)和犯罪分子在用户存取数据库时猎取用户名和用户口令,然后假冒合法用户偷取、修改甚至破坏用户数据。
- 数据库管理系统提供的安全措施主要包括用户身份鉴别、存取控制和视图等技术。
-
数据库中重要或敏感的数据被泄露
- 黑客和敌对分子千方百计盗窃数据库中的重要数据,一些机密信息被暴露。
- 数据库管理系统提供的主要技术有强制存取控制、数据加密存储和加密传输等。
- 审计日志分析。
-
安全环境的脆弱性
- 数据库的安全性与计算机系统的安全性紧密联系。
- 计算机硬件、操作系统、网络系统等的安全性。
- 建立一套可信(Trusted)计算机系统的概念和标准。
4.1.2 安全标准简介
1985 年美国国防部(DoD)正式颁布《DoD 可信计算机系统评估准则》(简称 TCSEC 或 DoD85)。不同国家基于 TCSEC 概念建立了评估准则,包括:
- 欧洲的信息技术安全评估准则(ITSEC)
- 加拿大的可信计算机产品评估准则(CTCPEC)
- 美国的信息技术安全联邦标准(FC)
1993 年,CTCPEC、FC、TCSEC 和 ITSEC 联合行动,解决原标准中概念和技术上的差异,称为 CC(Common Criteria)项目。1999 年,CC V2.1 版被 ISO 采用为国际标准,2001 年,CC V2.1 版被我国采用为国家标准。目前 CC 已基本取代了 TCSEC,成为评估信息产品安全性的主要标准。
信息安全标准的发展历史
graph TB
subgraph "信息安全标准的发展历史"
A("1985年美国国防部可信计算机系统评估准则 (TCSEC)")
B("1991年欧洲信息技术安全评估准则 (ITSEC)")
C("1993年加拿大可信计算机产品评估准则 (CTCPEC)")
D("1993年美国信息技术安全联邦标准 (FC) 草案")
E("通用准则 (CC) V1.0 1996年, V2.0 1998年, V2.1 1999年")
F("1999年 CC V2.1 成为国际标准 (ISO15408)")
A --> E
B --> E
C --> E
D --> E
E --> F
end
TCSEC 标准
1991 年 4 月,美国国家计算机安全中心(NCSC)颁布了《可信计算机系统评估标准关于可信数据库系统的解释》(TDI),也称紫皮书。它将 TCSEC 扩展到数据库管理系统,定义了数据库管理系统的设计与实现中需满足的安全性级别评估标准。
TCSEC/TDI 标准的基本内容
TCSEC/TDI 从四个方面来描述安全性级别划分的指标:
- 安全策略
- 责任
- 保证
- 文档
TCSEC/TDI 安全级别划分
| 安全级别 | 定义 |
|---|---|
| A1 | 验证设计(Verified Design) |
| B3 | 安全域(Security Domains) |
| B2 | 结构化保护(Structural Protection) |
| B1 | 标记安全保护(Labeled Security Protection) |
| C2 | 受控的存取保护(Controlled Access Protection) |
| C1 | 自主安全保护(Discretionary Security Protection) |
| D | 最小保护(Minimal Protection) |
TCSEC/TDI 分为四组(division)七个等级:
- D
- C(C1,C2)
- B(B1,B2,B3)
- A(A1)
级别按系统可靠或可信程度逐渐增高,各安全级别之间具有一种偏序向下兼容的关系,即较高安全性级别提供的安全保护包含较低级别的所有保护要求,同时提供更多或更完善的保护能力。
D 级
- 将一切不符合更高标准的系统均归于 D 组。
- 典型例子:DOS 是安全标准为 D 的操作系统,DOS 在安全性方面几乎没有什么专门的机制来保障。
C1 级
- 非常初级的自主安全保护,能够实现对用户和数据的分离,进行自主存取控制(DAC),保护或限制用户权限的传播。
- 现有的商业系统稍作改进即可满足。
C2 级
- 安全产品的最低档次,提供受控的存取保护,将 C1 级的 DAC 进一步细化,以个人身份注册负责,并实施审计和资源隔离。
- 典型例子:Windows 2000,Oracle 7。
B1 级
- 标记安全保护,对系统的数据加以标记,对标记的主体和客体实施强制存取控制(MAC)、审计等安全机制。
- 典型例子:
- 操作系统:惠普公司的 HP-UX BLS release 9.09+
- 数据库:Oracle 公司的 Trusted Oracle 7,Sybase 公司的 Secure SQL Server version 11.0.6
B2 级
- 结构化保护,建立形式化的安全策略模型并对系统内的所有主体和客体实施 DAC 和 MAC。
B3 级
- 安全域,该级的 TCB 必须满足访问监控器的要求,审计跟踪能力更强,并提供系统恢复过程。
A1 级
- 验证设计,即提供 B3 级保护的同时给出系统的形式化设计说明和验证以确信各安全保护真正实现。
CC 标准
CC 提出国际公认的表述信息技术安全性的结构,把信息产品的安全要求分为:
- 安全功能要求
- 安全保证要求
CC 文本组成
- 简介和一般模型:有关术语、基本概念和一般模型以及与评估有关的一些框架。
- 安全功能要求:列出了一系列类、子类和组件。
- 安全保证要求:列出了一系列保证类、子类和组件,提出了评估保证级(Evaluation Assurance Level,EAL),从 EAL1 至 EAL7 共分为七级。
以上内容总结了数据库安全性的不安全因素、安全标准简介以及 TCSEC 和 CC 标准的详细内容和历史发展。
数据库安全性控制
数据库安全性控制是保护数据库系统免受未经授权的访问、泄露、篡改和破坏的关键措施。下面分别讲解几种主要的数据库安全性控制方法:
1. 用户身份鉴别
用户身份鉴别(Authentication)是验证用户身份的过程,确保访问数据库的用户是经过授权的合法用户。常用的方法包括:
- 用户名和密码:最基本的方法,通过匹配用户输入的用户名和密码来验证身份。
- 多因素认证(MFA):结合两种或多种不同类型的认证方法,如密码加上短信验证码或生物特征识别(如指纹、面部识别)。
- 证书认证:使用数字证书来验证用户身份,通常用于更高安全要求的环境中。
- 生物特征识别:利用用户的生物特征(如指纹、虹膜扫描、面部识别)进行身份验证。
2. 存取控制
存取控制(Access Control)是限制用户对数据库资源的访问权限,确保只有授权用户才能执行特定操作。主要方法包括:
- 自主存取控制(DAC):由资源所有者决定谁可以访问其资源,基于访问控制列表(ACL)或权限矩阵。
- 强制存取控制(MAC):基于系统定义的策略,不允许用户自行决定权限,通常用于高安全性需求的环境。
3. 自主存取控制方法( 重点掌握 SQL )
自主存取控制(DAC, Discretionary Access Control)允许资源所有者(通常是数据库用户)控制对其资源的访问。主要方法包括:
- 访问控制列表(ACL):每个资源都有一个列表,列出允许访问该资源的用户及其权限。
- 权限矩阵:一种二维表格,行表示用户,列表示资源,表格中的值表示用户对资源的访问权限。
4. 授权:授予与收回
授权(Authorization)是指授予或收回用户对数据库资源的访问权限。包括以下操作:
- 授予权限(GRANT):数据库管理员或资源所有者授予用户特定的权限,如 SELECT、INSERT、UPDATE 等。
- 收回权限(REVOKE):撤销先前授予的权限,防止用户继续访问资源。
授权和收回权限是数据库安全性控制的重要环节。通过 SQL 语句,数据库管理员(DBA)或资源所有者可以授予用户特定的权限,或撤销用户先前的权限。下面详细讲解这部分涉及的 SQL 操作,并提供一个表格和示例代码。
授予权限(GRANT)
GRANT 语句用于将特定权限授予用户或角色。常见的权限包括 SELECT、INSERT、UPDATE、DELETE 等。
语法:
GRANT privilege [, ...]
ON object
TO user_or_role [, ...]
[WITH GRANT OPTION];
privilege:要授予的权限类型,如SELECT、INSERT等。object:权限作用的数据库对象,如表、视图等。user_or_role:接受权限的用户或角色。WITH GRANT OPTION:允许被授予权限的用户进一步将该权限授予他人。
收回权限(REVOKE)
REVOKE 语句用于撤销先前授予的权限,防止用户继续访问或操作数据库对象。
语法:
REVOKE privilege [, ...]
ON object
FROM user_or_role [, ...];
privilege:要撤销的权限类型。object:权限作用的数据库对象。user_or_role:被撤销权限的用户或角色。
授权与收回权限的 SQL 语法
| 操作 | 语法 |
|---|---|
| 授予权限 | GRANT privilege [, ...] ON object TO user_or_role [, ...] [WITH GRANT OPTION]; |
| 收回权限 | REVOKE privilege [, ...] ON object FROM user_or_role [, ...]; |
示例代码
创建示例数据库和表
-- 创建数据库
CREATE DATABASE company_db;
-- 使用数据库
USE company_db;
-- 创建示例表
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
hire_date DATE
);
-- 创建用户
CREATE USER 'user1'@'localhost' IDENTIFIED BY 'password1';
CREATE USER 'user2'@'localhost' IDENTIFIED BY 'password2';
授予权限
-- 授予user1对employees表的SELECT权限
GRANT SELECT ON employees TO 'user1'@'localhost';
-- 授予user2对employees表的INSERT和UPDATE权限,并允许其将这些权限授予其他用户
GRANT INSERT, UPDATE ON employees TO 'user2'@'localhost' WITH GRANT OPTION;
收回权限
-- 撤销user1对employees表的SELECT权限
REVOKE SELECT ON employees FROM 'user1'@'localhost';
-- 撤销user2对employees表的INSERT和UPDATE权限
REVOKE INSERT, UPDATE ON employees FROM 'user2'@'localhost';
最佳实践
- 最小权限原则:只授予用户完成任务所需的最小权限,减少潜在的安全风险。
- 定期审计:定期检查用户权限,确保只有需要的用户拥有必要的权限。
- 使用角色:通过角色管理权限,简化权限分配和管理。例如,可以创建一个
readonly角色,仅具有SELECT权限,然后将该角色分配给需要只读访问的用户。 - 谨慎使用 WITH GRANT OPTION:仅在必要时使用
WITH GRANT OPTION,避免权限链传递过长,增加管理难度和安全风险。 - 分层管理:将权限分层次管理,如开发、测试和生产环境分开管理权限,避免测试环境权限影响生产环境安全。
通过以上的方法和示例代码,可以有效地管理数据库用户的权限,确保数据库的安全性和稳定性。
5. 数据库角色
数据库角色(Role)是一种简化权限管理的方法,通过将多个权限分组并赋予一个角色,然后将该角色分配给用户。角色的优点包括:
- 简化管理:可以一次性管理多个权限,减少重复工作。
- 灵活性:用户可以根据需要随时添加或删除角色,从而改变其权限。
- 安全性:通过角色控制权限分配,减少误操作的风险。
6. 强制存取控制方法
强制存取控制(MAC, Mandatory Access Control)是一种更严格的存取控制方法,常用于高安全性环境,如政府或军事系统。特点包括:
- 基于安全级别:每个资源和用户都有一个安全级别或标签,系统根据这些标签决定是否允许访问。
- 不可更改:用户不能自行更改权限,所有权限由系统策略决定。
- 高级策略:如“最小特权原则”和“需要知道原则”,确保用户只能访问其工作所需的最少资源。
总结
数据库安全性控制是保护数据库系统的关键环节,通过用户身份鉴别、存取控制、自主存取控制、授权、数据库角色和强制存取控制等方法,确保数据的机密性、完整性和可用性。每种方法都有其独特的优势和适用场景,需要根据具体需求和环境选择合适的控制措施。
第五章、数据库完整性
(重点三个完整性,触发器会有 SQL)
概述
- 什么是数据库的完整性?
数据库的完整性是指数据的正确性和相容性。数据的正确性是值数据是符合现实世界语义、反映当前实际状况的;数据的相容性是指数据库同一对象在不同关系表中的数据是符合逻辑的。 - DBMS 的完整性控制机制应具有哪三个方面的功能?
a. 定义功能;
b. 检查功能;
c. 违约处理功能。 - 定义数据库完整性一般由 SQL 的 _____ 语句实现的?
DDL(数据库模式定义语言)
实体完整性
- 如何在 SQL 中定义实体完整性?
CREATE TABLE Student
(Sno CHAR(9) PRIMARY KEY, // 在列级定义主码
/*...*/
);
CREATE TABLE SC
(Sno CHAR(9) NOT NULL,
Cno CHAR(9) NOT NULL,
/*...*/
PRIMARY KEY (Sno, Cno) // 属性组只能在表级定义主码
);
参照完整性
- 如何在 SQL 中定义参照完整性?
CREATE TABLE SC
(Sno CHAR(9) NOT NULL,
Cno CHAR(9) NOT NULL,
/*...*/
PRIMARY KEY (Sno, Cno),
FOREIGN KEY (Sno) REFERENCES Student(Sno), // 在表级定义参照完整性
FOREIGN KEY (Cno) REFERENCES Course(Cno)
);
注意:
- 定义参照完整性的时候注意定义的顺序,被参照表要先被定义。
用户定义的完整性
- 定义 属性 上的约束条件。
属性值的限制有三种:列值非空(NOT NULL),列值唯一(UNIQUE),检查列值是否满足一个条件表达式(CHECK短语)。
CREATE TABLE Student
(Sno CHAR(9) NOT NULL,
Dname CHAR(9) UNIQUE NOT NULL, // 唯一且不能取空值
// 性别只允许取'男'或'女'
Ssex CHAR(2) CHECK(Ssex IN ('男','女')),
// 限定成绩的取值范围
Grade SMALLINT CHECK(Grade >= 0 AND Grade <= 100),
/*...*/
);
- 定义 元组 上的约束条件。
// 例:学生性别是男时,其名字不能以 Ms. 打头
CREATE TABLE Student
(Sno CHAR(9),
Sname CHAR(8) NOT NULL,
Ssex CHAR(2),
/*...*/
// 定义两个属性值之间的约束条件
CHECK (Ssex='女' OR Sname NOT LIKE 'Ms.%')
);
完整性约束命名子句
- 定义完整性约束命名子句。
CONSTRAINT <完整性约束条件名> <完整性约束条件>
其中<完整性约束条件>包括NOT NULL、UNIQUE、PRIMARY KEY、FOREIGN KEY、CHECK短语等。 - 修改表中的完整性约束子句。
a. 去掉某个完整性约束子句:
ALTER TABLE <表名> DROP CONSTRAINT <完整性约束条件名>;
b. 增加新的完整性约束子句:
ALTER TABLE <表名> ADD CONSTRAINT <完整性约束条件名> <完整性约束条件>;
域中的完整性限制
- 定义域,建立并修改该域应该满足的完整性约束条件。
// 例:建立域的同时声明取值范围
CREATE DOMAIN GenderDomain CHAR(2)
CHECK (VALUE IN ('男','女'));
// 例:建立域的同时对其中的限制命名
CREATE DOMAIN GenderDomain CHAR(2)
CONSTRAINT GD CHECK (VALUE IN ('男','女'));
// 删除限制条件
ALTER DOMAIN GenderDomain
DROP CONSTRAINT GD;
// 增加限制条件
ALTER DOMAIN GenderDomain
ADD CONSTRAINT GDD CHECK (VALUE IN ('1','0'));
6. 断言
- 定义断言的格式?
CREATE ASSERTION <断言名> <CHECK 子句>;
其中<CHECK 子句>中的约束条件与WHERE子句的条件表达式类似。
// 例:限制每一门课程最多 60 名学生选修
CREATE ASSERTION ASSE_SC_CNUM1
CHECK(60 >= ALL(SELECT count(*)
FROM SC
GROUP BY cno)
);
- 删除断言的格式?
DROP ASSERTION <断言名>;
触发器
触发器(Trigger)指的是用户定义在关系表上的一类由事件驱动的特殊过程,任何用户对表的增删改操作均由服务器自动激活相应的触发器,触发器类似于完整性约束,但可以实施更为复杂的检查和操作,具有更精细和强大的数据控制能力
触发器的功能是在特定系统事件发生时,对规则的条件进行检查,若条件成立则执行规则中的动作,否则不执行
定义触发器
格式
create trigger <trigger name>
{before | after} <event> on <table name>
referencing new | old row as <variable>
for each {row | statement}
[when <trigger condition>] <trigger action body>
其中,<trigger name> 可以带或不带模式名,<event> 可以是 INSERT、DELETE、UPDATE 或几个事件的组合,只有当 trigger condition 被满足时,触发器被激活,才能让触发动作体被执行,若省略 WHERE 子句则会无条件触发动作体
触发器只能定义在基本表上,不能定义在视图上,当基本表的数据发送变化时,将激活定义在该表上相应触发事件的触发器
触发动作体
触发动作体可以是匿名的 PL/SQL 过程块,也可以是对已创建存储过程的调用,若为行级触发器,则用户可以在过程体中使用 NEW 和 OLD 引用事件之后的新值和之前的旧值进行引用,否则不能
若触发动作体失败,激活触发器的事件就会终止执行,触发器的目标表或触发器可能影响的其他对象不发生任何变化
触发器类型
按照触发器类型定义行级触发器(FOR EACH ROW)和语句级触发器(FOR EACH STATEMENT)
- 行级触发器
- 语句级触发器
示例
当改变了 department 表中的 dept_name 值时,更新 instructor 中的相应值
create trigger department_t
after update of dept_name on depeartment
referencing
old row as old_tuple
new row as new_tuple
for each row
update instructor
set dept_name = new_tuple.name
where dept_name = old_tuple.name;
在 CS Building 中办公的系预算不能低于 10000,若低于则改成 10000
create trigger budget_t
before insert or update of budget on department
referencing
old row as old_tuple
new row as new_tuple
for each row
begin
if new_tuple.building = 'CS Building' and new_tuple.budget < 10000
then new_tuple.budget := 10000;
end if;
end;
激活触发器
触发器的执行由触发事件激活的,并由数据库服务器自动执行
执行顺序
对于一个表中的多个触发器,按照如下顺序执行,多个 BEFORE 或 AFTER 触发器之间可以无序执行
- 执行该表上的
BEFORE触发器 - 激活触发器的
SQL语句 - 执行触发器的
AFTER触发器
删除触发器
格式
drop trigger <trigger name> on <table name>;
权限
只有具有相应权限的用户可以删除相应的触发器
第六章、关系数据理论( 考概念 )
范式考:给你一个关系模式,你判断符合第几范式
问题的提出
关系式数据库逻辑设计
- 针对具体问题,如何构造一个适合于它的数据模式
- 数据库逻辑设计的工具——关系数据库的规范化理论
关系模式由五部分组成,是一个五元组
R(U, D, DOM, F)
-
关系名 R 是符号化的元组语义
-
U 为一组属性
-
D 为属性组 U 中的属性所来自的域
-
DOM 为属性到域的映射
-
F 为属性组 U 上的一组数据依赖
-
由于 D、DOM 与模式设计关系不大,因此在本章中把关系模式看做一个三元组:
R<U, F>
-
作为二维表,关系要符合一个最基本的条件:每个分量必须是不可分开的数据项。满足了这个条件的模式就属于第一范式(1NF)
数据依赖
- 是一个关系内部属性与属性之间的一种约束关系
- 通过属性之间值的相等与否体现出来的数据间相互依赖
- 是现实世界属性之间相互联系的抽象
- 是数据内在的性质
- 是语义的体现
数据依赖的主要类型 (知道)
- 函数依赖(Functional Dependency,简记为 FD)
- 多值依赖(Multi-Valued Dependency,简记为 MVD)
函数依赖:
函数依赖普遍存在于现实生活中
- 描述一个学生关系,可以有学号、姓名、系名等属性。
- 一个学号只对应一个学生,一个学生只在一个系中学习
- “学号”值确定后,学生的姓名及所在系的值就被唯一确定。
- Sname = f(Sno),Sdept = f(Sno)
- 即 Sno 函数决定 Sname
- Sno 函数决定 Sdept
- 记作 Sno→Sname,Sno→Sdept
例 [6.1] 建立一个描述学校教务的数据库。
-
涉及的对象包括:
- 学生的学号(Sno)
- 所在系(Sdept)
- 系主任姓名(Mname)
- 课程号(Cno)
- 成绩(Grade)
-
假设学校教务系统数据库模式用一个单一的关系模式 Student 来表示,则该关系模式的属性集合为:
U ={Sno, Sdept, Mname, Cno, Grade}
-
现实世界的已知事实(语义):
- 一个系有若干学生, 但一个学生只属于一个系;
- 一个系只有一名(正职)负责人;
- 一个学生可以选修多门课程,每门课程有若干学生选修;
- 每个学生学习每一门课程有一个成绩。
-
由此可得到属性组 U 上的一组函数依赖 F:
F=\{Sno→Sdept, Sdept→Mname, (Sno, Cno)→ Grade\}
graph TD;
subgraph f3;
Sno[Sno]
Cno[Cno]
end;
Sdept[Sdept];
Mname[Mname];
Grade[Grade];
Sno --> Sdept;
f3 --> Grade;
Sdept --> Mname;
- 关系模式 Student <U, F> 中存在的问题:
-
数据冗余
-
浪费大量的存储空间
每一个系主任的姓名重复出现,重复次数与该系所有学生的所有课程成绩出现次数相同。
-
-
更新异常(Update Anomalies)
-
数据冗余 ,更新数据时,维护数据完整性代价大。
某系更换系主任后,必须修改与该系学生有关的每一个元组。
-
-
插入异常(Insertion Anomalies)
- 如果一个系刚成立,尚无学生,则无法把这个系及其系主任的信息存入数据库。
-
删除异常(Deletion Anomalies)
- 如果某个系的学生全部毕业了, 则在删除该系学生信息的同时,把这个系及其系主任的信息也丢掉了。
结论:
- Student 关系模式不是一个好的模式。
- 一个“好”的模式应当不会发生插入异常、删除异常和更新异常,数据冗余应尽可能少。
原因:
- 由存在于模式中的某些数据依赖引起的。
解决方法:
-
用规范化理论改造关系模式来消除其中不合适的数据依赖
-
把这个单一的模式分成三个关系模式:
- S(Sno, Sdept, Sno → Sdept);
- SC(Sno, Cno, Grade,(Sno, Cno) → Grade);
- DEPT(Sdept, Mname, Sdept → Mname);
-
这三个模式都不会发生插入异常、删除异常的问题,数据的冗余也得到了控制。
规范化
(熟悉各个范式)
函数依赖
-
函数依赖
-
定义 6.1
设 ( R(U) ) 是一个属性集 (U ) 上的关系模式,( X ) 和 ( Y ) 是 ( U ) 的子集。若对于 ( R(U) ) 的任意一个可能的关系 ( r ),( r ) 中不可能存在两个元组在 ( X ) 上的属性值相等,而在 ( Y ) 上的属性值不等,则称“( X ) 函数确定 ( Y )”或“( Y ) 函数依赖于 ( X )”,记作 ( X \to Y )。- 例子
- Student(Sno, Sname, Ssex, Sage, Sdept)
- 假设不允许重名,则有:
\begin{align*} \text{Sno} & \to \text{Ssex} \\ \text{Sno} & \to \text{Sage} \\ \text{Sno} & \to \text{Sdept} \\ \text{Sno} & \leftarrow\rightarrow \text{Sname} \\ \text{Sname} & \to \text{Ssex} \\ \text{Sname} & \to \text{Sage} \\ \text{Sname} & \to \text{Sdept} \end{align*} - 但 ( \text{Ssex} \not\to \text{Sage} ),( $\text{Ssex} \not\to \text{Sdept} $)
若 ( $X \to Y $),并且 ( Y \to X ),则记为 ( X \leftarrow\rightarrow Y )。
若 ( Y ) 不函数依赖于 ( X ),则记为 ( X \not\to Y )。
函数依赖是语义范畴的概念,只能根据数据的语义来确定一个函数依赖。
例如“姓名 → 年龄”这个函数依赖只有在不允许有同名人的条件下成立。 - 例子
-
-
平凡函数依赖与非平凡函数依赖
-
( X \to Y ),但 ( Y \nsubseteq X ) 则称 ( X \to Y ) 是非平凡的函数依赖。
-
( $X \to Y $),但 ( Y \subseteq X ) 则称 ( X \to Y ) 是平凡的函数依赖。
对于任一关系模式,平凡函数依赖都是必然成立的,它不反映新的语义。
若不特别声明,我们总是讨论非平凡函数依赖。若 ( X \to Y ),则 ( X ) 称为这个函数依赖的决定因素(Determinant)。
若 ( X \to Y ),( Y \to X ),则记作 ( X \leftarrow\rightarrow Y )。
若 ( Y ) 不函数依赖于 ( X ),则记作 ( X \not\to Y )。
-
-
完全函数依赖与部分函数依赖
-
定义 6.2
在 ( R(U) ) 中,如果 ( X \to Y ),并且对于 ( X ) 的任何一个真子集 ( X' ),都有 ( $X’ \not\to Y $),则称 ( Y ) 对 ( X ) 完全函数依赖,记作 ( X_f \to Y )。
若 ( $X \to Y $),但 ( Y ) 不完全函数依赖于 ( X ),则称 ( Y ) 对 ( X ) 部分函数依赖,记作 ( X_p \to Y )。- 例子
-
在关系 SC(Sno, Cno, Grade) 中,有:
\begin{align*} \text{Sno} & \not\to \text{Grade} \\ \text{Cno} & \not\to \text{Grade} \\ (\text{Sno}, \text{Cno}) & \to_f \text{Grade} \\ (\text{Sno}, \text{Cno}) & \to_p \text{Sno} \\ (\text{Sno}, \text{Cno}) & \to_p \text{Cno} \end{align*}
-
- 例子
-
-
传递函数依赖
- 定义 6.3
在 ( R(U) ) 中,如果 ( X \to Y ) ( Y \nsubseteq X ),( Y \not\to X ),( Y \to Z ),( Z \nsubseteq Y ),则称 ($ Z$ ) 对 ($ X$ ) 传递函数依赖(transitive functional dependency)。记为:($ X \text{传递} \to Z $)。
注:如果 ( $Y \to X \),即 \( X \leftarrow\rightarrow Y$ ),则 ( Z ) 直接依赖于 ( $X $),而不是传递函数依赖。- 例子
- 在关系 Std(Sno, Sdept, Mname) 中,有:
\begin{align*} \text{Sno} & \to \text{Sdept} \\ \text{Sdept} & \to \text{Mname} \\ \text{Mname} & \text{传递函数依赖于} \text{Sno} \end{align*}
- 在关系 Std(Sno, Sdept, Mname) 中,有:
- 例子
- 定义 6.3
码
-
定义 6.4
设 K 为 R\langle U, F \rangle 中的属性或属性组合。若 K \to_F U,则 K 称为 R 的一个候选码(Candidate Key)。
如果 U 部分函数依赖于 K,即 K \to_P U,则 K 称为超码(Surpkey)。候选码是最小的超码,即 K 的任意一个真子集都不是候选码。
若关系模式 R 有多个候选码,则选定其中的一个作为主码(Primary key)。 -
主属性与非主属性
-
包含在任何一个候选码中的属性,称为主属性(Prime attribute)。
-
不包含在任何码中的属性称为非主属性(Nonprime attribute)或非码属性(Non-key attribute)。
-
全码:整个属性组是码,称为全码(All-key)。
-
例 6.2
- S(Sno, Sdept, Sage),单个属性 Sno 是码。
- SC(Sno, Cno, Grade) 中,(Sno, Cno) 是码。
-
例 6.3
- R(P, W, A)
- P:演奏者
- W:作品
- A:听众
- 一个演奏者可以演奏多个作品。
- 某一作品可被多个演奏者演奏。
- 听众可以欣赏不同演奏者的不同作品。
- 码为 (P, W, A),即 All-Key。
- R(P, W, A)
-
-
定义 6.5
关系模式 R 中属性或属性组 X 并非 R 的码,但 X 是另一个关系模式的码,则称 X 是 R 的外部码(Foreign key),也称外码。- 例子
- SC(Sno, Cno, Grade) 中,Sno 不是码。
- Sno 是 S(Sno, Sdept, Sage) 的码,则 Sno 是 SC 的外码。
- 例子
范式
-
范式
- 范式是符合某一种级别的关系模式的集合。关系数据库中的关系必须满足一定的要求,满足不同程度要求的为不同范式。
- 范式的种类:
- 第一范式 (1NF)
- 第二范式 (2NF)
- 第三范式 (3NF)
- BC 范式 (BCNF)
- 第四范式 (4NF)
- 第五范式 (5NF)
-
各种范式之间存在联系:
5NF \subset 4NF \subset BCNF \subset 3NF \subset 2NF \subset 1NF -
表示方式
- 某一关系模式 R 为第 n 范式,可简记为 R \in nNF。
- 一个低一级范式的关系模式,通过模式分解(schema decomposition)可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化(normalization)。
2NF
-
定义 6.6
若关系模式 R \in 1NF,并且每一个非主属性都完全函数依赖于任何一个候选码,则 R \in 2NF。-
例 6.4
-
S-L-C(Sno, Sdept, Sloc, Cno, Grade),其中 Sloc 为学生的住处,并且每个系的学生住在同一个地方。S-L-C 的码为 (Sno, Cno)。
-
函数依赖有:
\begin{align*} (Sno, Cno) &\to_f Grade \\ Sno &\to Sdept, \quad (Sno, Cno) \to_p Sdept \\ Sno &\to Sloc, \quad (Sno, Cno) \to_p Sloc \\ Sdept &\to Sloc \end{align*}graph LR Grade -->|has| Sno Grade -->|has| Cno Sno -->|belongs to| Sdept Sno -->|has| Sloc Cno -->|belongs to| Sdept Cno -->|located at| Sloc Sdept --> Sloc
非主属性 Sdept、Sloc 并不完全依赖于码,因此关系模式 S-L-C 不属于 2NF。
-
-
-
一个关系模式不属于 2NF,会产生以下问题:
-
插入异常
- 如果插入一个新学生,但该生未选课,即该生无 Cno,由于插入元组时,必须给定码值,因此插入失败。
-
删除异常
- 如果 S4 只选了一门课 C3,现在他不再选这门课,则删除 C3 后,整个元组的其他信息也被删除了。
-
修改复杂
- 如果一个学生选了多门课,则 Sdept、Sloc 被存储了多次。如果该生转系,则需要修改所有相关的 Sdept 和 Sloc,造成修改的复杂化。
-
-
出现这种问题的原因
- 例子中有两类非主属性:
- 一类如 Grade,它对码完全函数依赖。
- 另一类如 Sdept、Sloc,它们对码不是完全函数依赖。
- 例子中有两类非主属性:
-
解决方法:
-
用投影分解把关系模式 S-L-C 分解成两个关系模式:
\begin{align*} SC(Sno, Cno, Grade) \\ S-L(Sno, Sdept, Sloc) \end{align*}graph LR; subgraph SC; Sno; Cno; end; SC --> Grade;graph TD; Sno --> Sdept; Sno --> Sloc; Sdept --> Sloc;- SC 的码为 (Sno, Cno)
- SL 的码为 Sno
- 这样使得非主属性对码都是完全函数依赖了。
-
3NF
定义 6.7
设关系模式 ( R <U,F> \in 1NF ),若 ( R ) 中不存在这样的码 ( X )、属性组 ( Y ) 及非主属性 ( Z )(( Z \supseteq Y )),使得 ( X \rightarrow Y ), ( Y \rightarrow Z ) 成立且 ( Y \not\rightarrow X ) 不成立,则称 ( R <U,F> \in 3NF )。
- SC 没有传递依赖,因此 ( SC \in 3NF )。
- 对于关系模式 ( S-L ), ( Sno \rightarrow Sdept )( ( Sdept \not\rightarrow Sno ) ), ( Sdept \rightarrow Sloc ),可得 ( Sno \rightarrow Sloc )。
- 解决的办法是将 ( S-L ) 分解成:
- ( S-D(Sno, Sdept) \in 3NF )
- ( D-L(Sdept, Sloc) \in 3NF )
BCNF
BCNF(Boyce Codd Normal Form)由 Boyce 和 Codd 提出,比 3NF 更进了一步。通常认为 BCNF 是修正的第三范式,有时也称为扩充的第三范式。
定义 6.8
设关系模式 ( R <U,F> \in 1NF ),若 ( X \rightarrow Y ) 且 ( Y \subseteq X ) 时 ( X ) 必含有码,则 ( R <U,F> \in BCNF )。
BCNF 的关系模式具有以下性质:
-
所有非主属性都完全函数依赖于每个候选码。
-
所有主属性都完全函数依赖于每个不包含它的候选码。
-
没有任何属性完全函数依赖于非码的任何一组属性。
-
例 6.5 考察关系模式 ( C(Cno, Cname, Pcno) )
- 它只有一个码 ( Cno ),没有任何属性对 ( Cno ) 部分依赖或传递依赖,所以 ( C \in 3NF )。
- 同时 ( C ) 中 ( Cno ) 是唯一的决定因素,所以 ( C \in BCNF )。
-
例 6.6 关系模式 ( S(Sno, Sname, Sdept, Sage) )
- 假定 ( Sname ) 也具有唯一性,那么 ( S ) 就有两个码,这两个码都由单个属性组成,彼此不相交。
- 其他属性不存在对码的传递依赖与部分依赖,所以 ( S \in 3NF )。
- 同时 ( S ) 中除 ( Sno ), ( Sname ) 外没有其他决定因素,所以 ( S ) 也属于 BCNF。
-
例 6.7 关系模式 ( SJP(S, J, P) )
- ( S ) 是学生, ( J ) 表示课程, ( P ) 表示名次。每一个学生选修每门课程的成绩有一定的名次,每门课程中每一名次只有一个学生。
- 由语义可得到函数依赖: ( (S, J) \rightarrow P ), ( (J, P) \rightarrow S )。
- ( (S, J) ) 与 ( (J, P) ) 都可以作为候选码。
- 关系模式中没有属性对码传递依赖或部分依赖,所以 ( SJP \in 3NF )。
- 除 ( (S, J) ) 与 ( (J, P) ) 以外没有其他决定因素,所以 ( SJP \in BCNF )。
-
例 6.8 关系模式 ( STJ(S, T, J) )
- ( S ) 表示学生, ( T ) 表示教师, ( J ) 表示课程。每一教师只教一门课,每门课有若干教师,某一学生选定某门课,就对应一个固定的教师。
- 由语义可得到函数依赖: ( (S, J) \rightarrow T ), ( (S, T) \rightarrow J ), ( T \rightarrow J )。
- 因为没有任何非主属性对码传递依赖或部分依赖,所以 ( STJ \in 3NF )。
- 因为 ( T ) 是决定因素,而 ( T ) 不包含码,所以 ( STJ \in BCNF )。
对于不是 BCNF 的关系模式,仍然存在不合适的地方。非 BCNF 的关系模式也可以通过分解成为 BCNF。例如 STJ 可分解为 ST(S, T)与 TJ(T, J),它们都是 BCNF。
多值依赖
例 [6.9] 设学校中某一门课程由多个教师讲授,他们使用相同的一套参考书。每个教员可以讲授多门课程,每种参考书可以供多门课程使用。
用关系模式 Teaching(C, T, B)来表示课程 C、教师 T 和参考书 B 之间的关系。Teaching 具有唯一候选码(C, T, B),即全码。Teaching ∈ BCNF
定义 6.9
设 ( R(U) ) 是属性集 ( U ) 上的一个关系模式。( X, Y, Z ) 是 ( U ) 的子集,并且 ( Z = U - X - Y )。关系模式 ( R(U) ) 中多值依赖 ( X \rightarrow\rightarrow Y ) 成立,当且仅当对 ( R(U) ) 的任一关系 ( r ),给定的一对 ( (x, z) ) 值,有一组 ( Y ) 的值,这组值仅仅决定于 ( x ) 值而与 ( z ) 值无关。
4NF
定义 6.10
关系模式 ( R <U,F> \in 1NF ),如果对于 ( R ) 的每个非平凡多值依赖 ( X \rightarrow\rightarrow Y ) ( ( Y \not\subseteq X ) ), ( X ) 都含有码,则 ( R <U,F> \in 4NF )。
在例 6.10 的 WSC 中, ( W \rightarrow\rightarrow S ), ( W \rightarrow\rightarrow C ),他们都是非平凡多值依赖。而 ( W ) 不是码,关系模式 WSC 的码是 ( (W, S, C) ),即 All-key,因此 ( WSC \in 4NF )。可以把 WSC 分解成 WS(W, S),WC(W, C),其中 WS ∈ 4NF,WC ∈ 4NF。
范式总结 (考试必考)
1NF(第一范式)
第一范式是指数据库表中的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。
如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。第一范式的模式要求属性值不可再分裂成更小部分,即属性项不能是属性组合或是由一组属性构成。
简而言之,第一范式就是无重复的列。例如,由“职工号”“姓名”“电话号码”组成的表(一个人可能有一部办公电话和一部移动电话),这时将其 规范化为 1NF 可以将电话号码分为“办公电话”和“移动电话”两个属性,即职工(职工号,姓名,办公电话,移动电话)。
2NF(第二范式)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的 每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。
如果关系模型 R 为第一范式,并且 R 中的每一个非主属性完全函数依赖于 R 的某个候选键,则称 R 为第二范式模式(如果 A 是关系模式 R 的候选键的一个属性,则称 A 是 R 的主属性,否则称 A 是 R 的非主属性)。
例子:在选课关系表(学号,课程号,成绩,学分),关键字为组合关键字(学号,课程号),但由于非主属性 学分 仅依赖于课程号,对关键字(学号,课程号)只是部分依赖,而不是完全依赖
问题:此种方式会导致数据冗余以及更新异常等问题
解决办法:将其分为两个关系模式:学生表(学号,课程号,分数)和课程表(课程号,学分),新关系通过学生表中的外关键字课程号联系,在需要时进行连接。
3NF(第三范式)
如果关系模型 R 是第二范式,且 每个非主属性都不传递依赖于 R 的候选键,则称 R 是第三范式的模式。
以学生表(学号,姓名,课程号,成绩)为例,其中学生姓名无重名,所以该表有两个候选码(学号,课程号)和(姓名,课程号),故存在函数依赖:学号——> 姓名,(学号,课程号)——> 成绩,唯一的非主属性 成绩对码不存在部分依赖,也不存在传递依赖,所以属性属于第三范式。
BCNF(BC 范式)
它构建在第三范式的基础上,如果关系模型 R 是第一范式,且 每个属性都不传递依赖于 R 的候选键,那么称 R 为 BCNF 的模式。
假设仓库管理关系表(仓库号,存储物品号,管理员号,数量),满足一个管理员只在一个仓库工作;一个仓库可以存储多种物品,则存在如下关系:
(仓库号,存储物品号)——>(管理员号,数量)
(管理员号,存储物品号)——>(仓库号,数量)
所以,(仓库号,存储物品号)和(管理员号,存储物品号)都是仓库管理关系表的候选码,表中唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下决定关系:
(仓库号)——>(管理员号)
(管理员号)——>(仓库号)
即存在关键字段决定关键字段的情况,因此其不符合 BCNF。把仓库管理关系表分解为两个关系表仓库管理表(仓库号,管理员号)和仓库表(仓库号,存储物品号,数量),这样这个数据库表是符合 BCNF 的,并消除了删除异常、插入异常和更新异常。
4NF(第四范式)
设 R 是一个关系模型,D 是 R 上的多值依赖集合。如果 D 中存在凡多值依赖 X-> Y 时,X 必是 R 的超键,那么称 R 是第四范式的模式。
例如,职工表(职工编号,职工孩子姓名,职工选修课程),在这个表中,同一个职工可能会有多个职工孩子姓名,同样,同一个职工也可能会有多个职工选修课程,即这里存在着多值事实,不符合第四范式。如果要符合第四范式,只需要将上表分为两个表,使它们只有一个多值事实,例如职工表一(职工编号,职工孩子姓名),职工表二(职工编号,职工选修课程),两个表都只有一个多值事实,所以符合第四范式。
上述为网上搜集整理的资料
总结
- 第一范式:不存在可以分割的属性(比如电话可分为工作电话和个人电话)
- 第二范式:非主属性要完全依赖于主属性,不能存在主属性其中的一个就能决定非主属性的情况
- 第三范式:消除传递依赖(不 允许出现 学生学号+课程号-> 课程号-> 老师号)
- BCNF 范式:主属性不依赖于主属性
- 第四范式:要求把同一表内的多对多关系删除。
- 第五范式:从最终结构重新建立原始结构。
第七章、数据库设计 (大题)
知道哪个阶段做了什么事,一个大题,要求掌握需求分析,概念设计,物理设计,软工概论里面也有,所以这里只要掌握怎么做题
数据库系统概论(超详解!!!)第八节 数据库设计_数据库系统概论课程设计-CSDN 博客
放两个题目:
- 试述数据库设计的流程:

- 试述数据库设计过程中形成的数据库模式
- 在概念结构设计阶段,形成独立于各机器特点之外,独立于各个数据模型之外的 概念模型
- 在逻辑结构设计阶段,将概念结构设计阶段设计好的概念模型转化为与选用 DBMS 产品相适应的逻辑结构,形成数据库的逻辑模式,并根据用户的需求,安全性的考虑,建立必要的视图,形成数据库的 外模式
- 在物理结构设计阶段,根据关系数据库的特点和处理的需要,进行物理存储安排,建立索引,形成数据库的 内模式
- 数据字典的内容和作用是什么?

- 什么是数据库的概念结构?试述其特点和设计策略
-
①:特点
- 能真实、 充分地反映现实世界, 包括事物和事物之间的联系, 能满足用户对数据的处理要求, 是对现实世界的一个真实模型
- 易于理解, 从而可以用它和不熟悉计算机的用户交换意见, 用户的积极参与是数据库设计成功的关键
- 易于更改, 当应用环境和应用要求改变时, 容易对概念模型修改和扩充;
- 易于向关系、 网状、 层次等各种数据模型转换
②:设计策略
- 自顶向下, 即首先定义全局概念结构的框架, 然后逐步细化
- 自底向上, 即首先定义各局部应用的概念结构, 然后将它们集成起来, 得到全局概念结构
- 逐步扩张, 首先定义最重要的核心概念结构, 然后向外扩充, 以滚雪球的方式逐步生成其他概念结构, 直至总体概念结构
- 混合策略, 即将自顶向下和自底向上相结合, 用自顶向下策略设计一个全局概念结构的框架, 以它为骨架集成由自底向上策略中设计的各局部概念结构
第十章、数据库恢复技术 (重头)
事务
事务的基本概念
概念:事务(Transaction)是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
意义:事务是恢复和并发控制的基本单位。
如何定义:若用户没有显式地定义事务,则由 数据库管理系统 按默认规定自动划分事务。在 SQL 中,定义事务的语句一般有三条:
BEGIN TRANSACTION;
COMMIT;
ROLLBACK;
123
- 事务通常以
BEGIN TRANSACTION开始,以COMMIT或ROLLBACK结束。 COMMIT表示提交事务的所有操作,也就是说将事务中所有对数据库的更新都写到磁盘上的物理数据库中去。这时表示事务正常结束。ROLLBACK表示回滚,意味着系统将撤销事务中对数据库的所有已完成的操作,回滚到事务开始时的状态。
事务的 ACID 特性
事务的 ACID 特性:
- 原子性(Atomicity):事务中包括的所有操作要么都做,要么都不做。
- 一致性(Consistency):事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。也就是说数据库中只包含成功事务提交的结果。所以可见一致性和原子性是密切相关的。
- 隔离性(Isolation):并发执行的各个事务之间不能互相干扰。一个事务内部的操作及使用的数据对其他并发事务是隔离的。
- 持续性(Durability):一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。
意义
保证事务 ACID 特性是事务处理的任务,也就是数据库管理系统中恢复机制和并发控制机制的责任。
数据库恢复概述
-
故障是不可避免的
-
计算机硬件故障
-
软件的错误
-
操作员的失误
-
恶意的破坏
-
-
故障的影响
- 运行事务非正常中断,影响数据库中数据的正确性
- 破坏数据库,全部或部分丢失数据
-
数据库的恢复
- 数据库管理系统必须具有把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态)的功能,这就是数据库的恢复管理系统对故障的对策
-
恢复子系统是数据库管理系统的一个重要组成部分
-
恢复技术是衡量系统优劣的重要指标
故障的种类
事务内部的故障
在事务执行过程中发生故障(执行 SQL 的时候报错)
- 有的是可以通过事务程序本身发现的(下面转账的例子)
- 有的是非预期的,不能由事务程序处理的。
例 [1]:银行转账事务,把一笔钱从账户甲转到乙
BEGIN TRANSACTION
读账户甲的余额BALANCE;
BALANCE=BALANCE-AMOUNT;
/*AMOUNT 为转账金额*/
IF(BALANCE < 0 ) THEN{
打印‘金额不足,不能转账’;
/*事务内部可能造成事务被回滚的情况*/
ROLLBACK;
/*撤销刚才的修改,恢复事务*/
}ELSE{
读账户乙的余额BALANCE1;
BALANCE1=BALANCE1+AMOUNT;
写回BALANCE1;
COMMIT;
}
- 这个例子所包括的两个更新操作要么全部完成要么全部不做。否则就会使数据库处于不一致状态,例如只把账户甲的余额减少了而没有把账户乙的余额增加。
- 在这段程序中若产生账户甲余额不足的情况,应用程序可以发现并让事务滚回,撤销已作的修改,恢复数据库到正确状态。
- 事务内部更多的故障是非预期的,是不能由应用程序处理的。例如:
- 运算溢出
- 并发事务发生死锁而被选中撤销该事务
- 违反了某些完整性限制而被终止等
- 当我们后面提到事务故障时,指的就是这类 非预期的故障
事务故障意味着:
- 事务没有达到预期的终点(COMMIT 或者显式的 ROLLBACK)
- 数据库可能处于不正确状态
事务故障的恢复: 事务撤消(UNDO)
- 强制回滚(ROLLBACK)该事务
- 撤销该事务已经作出的任何对数据库的修改,使得该事务象根本没有启动一样
系统故障
数据库系统故障(mysql 闪退,系统蓝屏)
系统故障称为软故障,是指造成系统停止运转的任何事件,使得系统要重新启动。
- 整个系统的正常运行突然被破坏
- 所有正在运行的事务都非正常终止
- 不破坏数据库
- 内存中数据库缓冲区的信息全部丢失
系统故障的常见原因
- 特定类型的硬件错误(如 CPU 故障)
- 操作系统故障
- 数据库管理系统代码错误
- 系统断电
系统故障的恢复
- 发生系统故障时,一些尚未完成的事务的结果可能已送入物理数据库,造成数据库可能处于不正确状态。
- 恢复策略:系统重新启动时,恢复程序让所有非正常终止的事务回滚,强行撤消(UNDO)所有未完成事务
- 发生系统故障时,有些已完成的事务可能有一部分甚至全部留在缓冲区,尚未写回到磁盘上的物理数据库中,系统故障使得这些事务对数据库的修改部分或全部丢失
- 恢复策略:系统重新启动时,恢复程序需要重做(REDO)所有已提交的事务
- 总结:
- 做过的重做,没做完的撤回
介质故障
存储介质故障(硬盘坏了,宇宙射线导致比特位翻转,数据库数据丢失等)
介质故障称为硬故障,指外存故障
- 磁盘损坏
- 磁头损坏
- 瞬时强磁场干扰
介质故障破坏数据库或者部分数据库,并且影响正在存取这部分数据的所有事物
介质故障比前两种故障的可能性小得多,但是破坏性大得多
计算机病毒(了解)
勒索病毒导致数据被加密
- 计算机病毒是一种人为的故障或破坏,是一些恶作剧者研制的一种计算机程序
- 可以繁殖和传播,造成对计算机系统包括数据库的危害
计算机病毒的种类
- 小的病毒只有 20 条指令,不到 50B
- 大的病毒像一个操作系统,由上万条指令组成
计算机病毒的危害
- 有的病毒传播很快,一旦侵入系统就马上摧毁系统
- 有的病毒有较长的潜伏期,计算机在感染后数天或数月才开始发病
- 有的病毒感染系统所有的程序和数据
- 有的只对某些特定的程序和数据感兴趣
计算机病毒已成为计算机系统的主要威胁,自然也是数据库系统的主要威胁
数据库一旦被破坏仍要用恢复技术把数据库加以恢复。
故障总结
实际上这些故障对于数据库的影响只有两种
- 数据库本身被破坏(通常伴随数据丢失,由于外部因素)
- 数据不正确(数据库本身没有损坏,这是由于事务的运行被非正常终止导致)
针对数据库故障也只有两种恢复方式
- REDO(重做事务)
- 在损坏的那一刻之前已经完成的事务进行重做
- UNDO(撤销事务)
- 在损坏时正在执行的事务进行 UNDO
注意,这里讨论的数据库损坏是指数据库中原先没有数据的情况下,也就是从创建数据库开始直到故障发生
恢复的实现技术 (重点)
数据库恢复操作的基本原理: 冗余
- 利用存储在系统别处的冗余数据来重建数据库中已被破坏或不正确的那部分数据。
数据恢复的前提就是数据冗余,如果所有的数据都是唯一的,那么恢复就无从谈起,因为你根本不知道有发生过故障
这里的冗余指的不是数据的冗余,更多的是事务信息的冗余,在 mysql 中表现为所有事物都有对应的 BinLog,来记录所有事物的状态。
数据库实现恢复的技术相当复杂,一个大型的数据库产品,恢复子系统的代码要占全部代码的 10%以上。
恢复机制涉及的关键问题
- 如何建立冗余数据
- 数据转储(Backup)
- 登记日志文件(Logging)
- 如何利用这些冗余数据实施数据库恢复
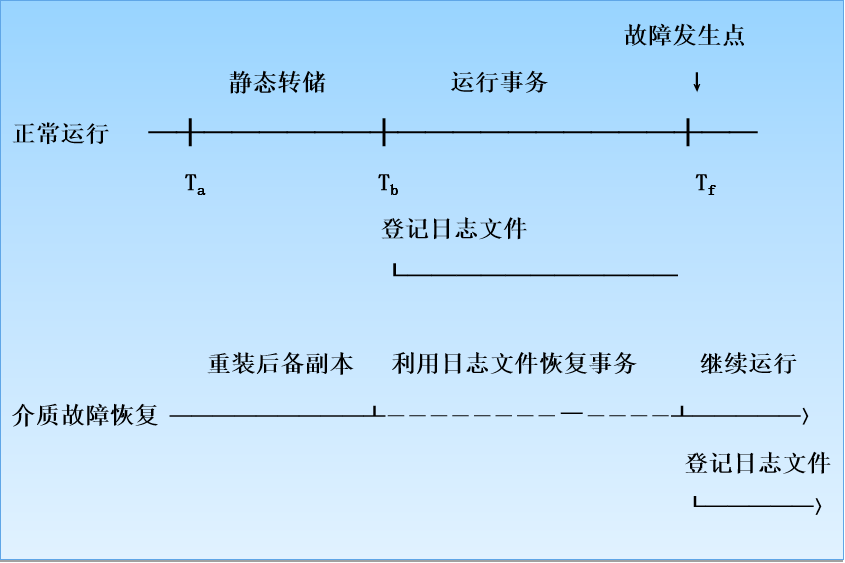
数据转储
什么是数据转储
数据转储就是备份数据库
-
转储是指数据库管理员定期地将整个数据库复制到磁带、磁盘或其他存储介质上保存起来的过程
-
备用的数据文本称为 后备副本(backup) 或 后援副本
-
数据库遭到破坏后可以将后备副本重新装入
-
重装后备副本只能将数据库恢复到转储时的状态
-
要想恢复到故障发生时的状态,必须重新运行自转储以后的所有更新事务
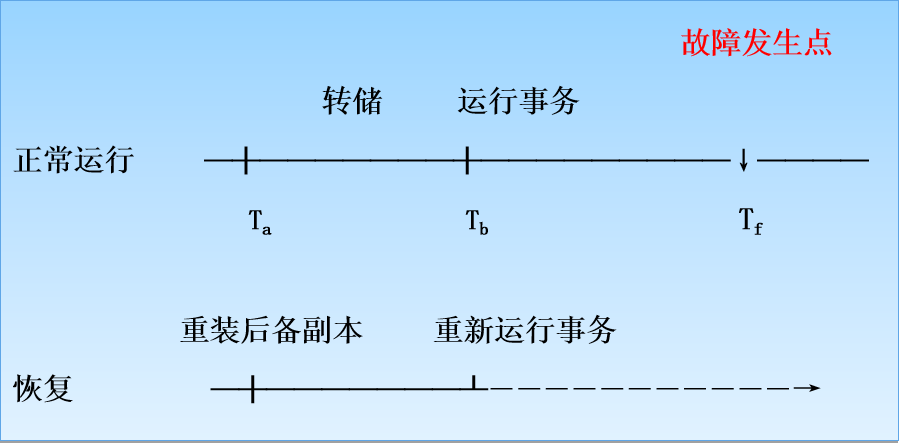
上图中:
- 系统在 Ta 时刻停止运行事务,进行数据库转储
- 在 Tb 时刻转储完毕,得到 Tb 时刻的数据库一致性副本
- 系统运行到 Tf 时刻发生故障
- 为恢复数据库,首先由数据库管理员重装数据库后备副本,将数据库恢复至 Tb 时刻的状态
- 重新运行自 Tb~Tf 时刻的所有更新事务,把数据库恢复到故障发生前的一致状态
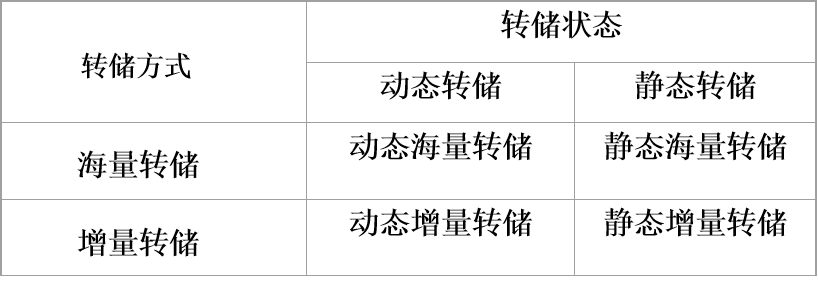
转储方法
-
静态转储和动态转储
静态转储:
在数据库没有任何事物运行的时候进行转储
在转储开始时数据库处于一致状态(数据已经完成写入),在转储结束前都不可以进行读写。
得到的是完全数据一致的副本
- 优点:
- 实现简单
- 缺点:
- 转储过程降低了数据库的可用性
动态转储:
在数据库运行时进行并行转储
转储时不影响事务的正常进行,不会降低数据库可用性
但是不保证数据库的转储结果一定是同步的(一致的)
-
海量转储与增量转储
海量转储:
每次转储全部数据库
增量转储:
只转储上次转储后更新过的数据
比较:
从恢复角度看,使用海量转储得到的后备副本进行恢复往往更方便
如果数据库很大,事务处理又十分频繁,则增量转储方式更实用更有效
-
转储方法小结
登记日志文件
什么是日志文件:
日志文件就是对数据库操作的记录文件
- 日志文件(log file)是用来记录事务对数据库的更新操作的文件
日志文件的格式:
- 以记录为单位的日志文件
- 以数据块为单位的日志文件
-
日志文件的格式和内容
-
以记录为单位的日志文件内容
-
各个事务的开始标记(BEGIN TRANSACTION)
-
各个事务的结束标记(COMMIT 或 ROLLBACK)
-
各个事务的所有更新操作
以上均作为日志文件中的一个日志记录 (log record)
-
以记录为单位的日志文件,每条日志记录的内容
-
事务标识(标明是哪个事务)
-
操作类型(插入、删除或修改)
-
操作对象(记录 ID、Block NO.)
-
更新前数据的旧值(对插入操作而言,此项为空值)
-
更新后数据的新值(对删除操作而言, 此项为空值)
-
-
-
以数据块为单位的日志文件,每条日志记录的内容
- 事务标识
- 被更新的数据块
-
-
日志文件的作用
-
进行事务故障恢复
-
进行系统故障恢复
-
协助后备副本进行介质故障恢复
-
-
登记日志文件
-
为保证数据库是可恢复的,登记日志文件时必须遵循两条原则
- 登记的次序严格按并发事务执行的时间次序
- 必须先写日志文件,后写数据库
- 写日志文件操作:把表示这个修改的日志记录写到 日志文件中
- 写数据库操作:把对数据的修改写到数据库中
-
为什么先写日志文件:
- 写数据库和写日志文件是两个不同的操作
- 在这两个操作之间可能发生故障
- 如果先写了数据库修改,而在日志文件中没有登记下这个修改,则以后就无法恢复这个修改了
- 如果先写日志,但没有修改数据库,按日志文件恢复时只不过是多执行一次不必要的 UNDO 操作,并不会影响数据库的正确性
恢复策略
事务故障的恢复
事务故障:事务在运行到正常结束前被终止
恢复方法:
- 由恢复子系统利用日志文件撤消(UNDO)此事务已对数据库进行的修改
事务故障的恢复由系统自动完成,对用户是透明的,不需要用户干预
事务故障的恢复步骤
- 反向扫描文件日志(即从最后向前扫描日志文件),查找该事务的更新操作。
- 对该事务的更新操作执行逆操作。即将日志记录中“更新前的值” 写入数据库。
- 插入操作, “更新前的值”为空,则相当于做删除操作
- 删除操作,“更新后的值”为空,则相当于做插入操作
- 若是修改操作,则相当于用修改前值代替修改后值
- 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理。
- 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了。
系统故障的恢复
系统故障造成数据库不一致状态的原因
- 未完成事务对数据库的更新可能已写入数据库
- 已提交事务对数据库的更新可能还留在缓冲区没来得及写入数据库
恢复方法:
- Undo 故障发生时未完成的事务
- Redo 已完成的事务
系统故障的恢复由系统在重新启动时自动完成,不需要用户干预
系统故障的恢复步骤:
- 正向扫描日志文件(即从头扫描日志文件)
- 重做(REDO) 队列: 在故障发生前已经提交的事务
- 这些事务既有 BEGIN TRANSACTION 记录,也有 COMMIT 记录
- 撤销 (UNDO)队列: 故障发生时尚未完成的事务
- 这些事务只有 BEGIN TRANSACTION 记录,无相应的 COMMIT 记录
- 重做(REDO) 队列: 在故障发生前已经提交的事务
- 对撤销(UNDO)队列事务进行撤销(UNDO)处理
- 反向扫描日志文件,对每个撤销事务的更新操作执行逆操作
- 即将日志记录中“更新前的值”写入数据库
- 对重做(REDO)队列事务进行重做(REDO)处理
- 正向扫描日志文件,对每个重做事务重新执行登记的操作
- 即将日志记录中“更新后的值”写入数据库
介质故障的恢复
- 重装数据库
- 重做已完成的事务
- 装入最新的后备数据库副本(离故障发生时刻最近的转储副本) ,使数据库恢复到最近一次转储时的一致性状态。
- 对于静态转储的数据库副本,装入后数据库即处于一致性状态
- 对于动态转储的数据库副本,还须同时装入转储时刻的日志文件副本,利用恢复系统故障的方法(即 REDO+UNDO),才能将数据库恢复到一致性状态。
- 装入有关的日志文件副本(转储结束时刻的日志文件副本) ,重做已完成的事务。
- 首先扫描日志文件,找出故障发生时已提交的事务的标识,将其记入重做队列。
- 然后正向扫描日志文件,对重做队列中的所有事务进行重做处理。即将日志记录中“更新后的值”写入数据库。
- 装入最新的后备数据库副本(离故障发生时刻最近的转储副本) ,使数据库恢复到最近一次转储时的一致性状态。
介质故障的恢复需要数据库管理员介入
数据库管理员的工作
- 重装最近转储的数据库副本和有关的各日志文件副本
- 执行系统提供的恢复命令
具体的恢复操作仍由数据库管理系统完成
具有检查点的恢复技术 (重点,图)
问题的提出
- 搜索整个日志将耗费大量的时间
- 重做处理:重新执行,浪费了大量时间
- 解决方案:具有检查点(checkpoint)的恢复技术
- 在日志文件中增加检查点记录(checkpoint)
- 增加重新开始文件
- 恢复子系统在登录日志文件期间动态地维护日志
检查点技术
检查点记录的内容:
- 建立检查点时刻所有正在执行的事务清单
- 这些事务最近一个日志记录的地址
重新开始文件的内容
-
记录各个检查点记录在日志文件中的地址
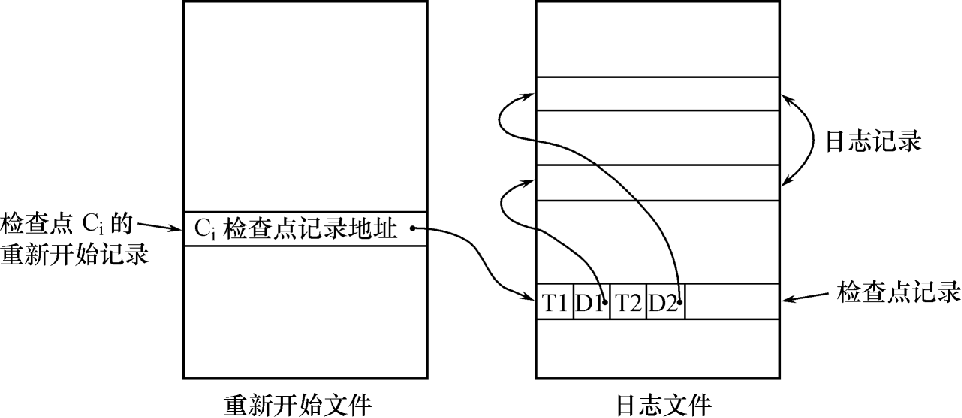
动态维护日志文件的方法
- 周期性地执行如下操作:建立检查点,保存数据库状态。具体步骤是:
- 将当前日志缓冲区中的所有日志记录写入磁盘的日志文件上
- 在日志文件中写入一个检查点记录
- 将当前数据缓冲区的所有数据记录写入磁盘的数据库中
- 把检查点记录在日志文件中的地址写入一个重新开始文件
恢复子系统可以定期或不定期地建立检查点, 保存数据库状态
- 定期:按照预定的一个时间间隔,如每隔一小时建立一个检查点
- 不定期:按照某种规则,如日志文件已写满一半建立一个检查点
利用检查点的恢复策略
使用检查点方法可以改善恢复效率
- 当事务 T 在一个检查点之前提交,T 对数据库所做的修改已写入数据库
- 写入时间是在这个检查点建立之前或在这个检查点建立之时
- 在进行恢复处理时,没有必要对事务 T 执行重做操作
系统出现故障时,恢复子系统将根据事务的不同状态采取不同的恢复策略
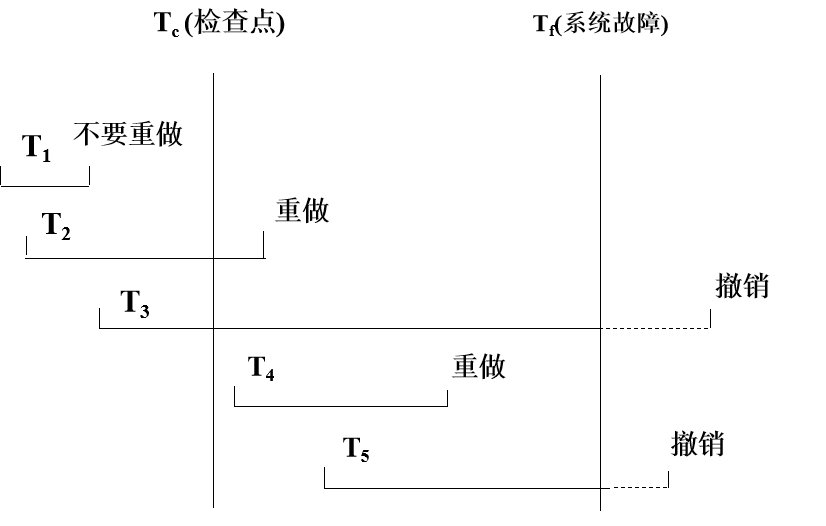
- T1:在检查点之前提交
- T2:在检查点之前开始执行,在检查点之后故障点之前提交
- T3:在检查点之前开始执行,在故障点时还未完成
- T4:在检查点之后开始执行,在故障点之前提交
- T5:在检查点之后开始执行,在故障点时还未完成
恢复策略
- T3 和 T5 在故障发生时还未完成,所以予以撤销
- T2 和 T4 在检查点之后才提交,它们对数据库所做的修改在故障发生时可能还在缓冲区中,尚未写入数据库,所以要重做
- T1 在检查点之前已提交,所以不必执行重做操作
利用检查点的恢复步骤
- 从重新开始文件中找到最后一个检查点记录在日志文件中的地址,由该地址在日志文件中找到最后一个检查点记录
- 由该检查点记录得到检查点建立时刻所有正在执行的事务清单 ACTIVE-LIST
- 建立两个事务队列
- UNDO-LIST
- REDO-LIST
- 把 ACTIVE-LIST 暂时放入 UNDO-LIST 队列,REDO 队列暂为空。
- 建立两个事务队列
- 从检查点开始正向扫描日志文件,直到日志文件结束
- 如有新开始的事务 Ti,把 Ti 暂时放入 UNDO-LIST 队列
- 如有提交的事务 Tj,把 Tj 从 UNDO-LIST 队列移到 REDO-LIST 队列; 直到日志文件结束
- 对 UNDO-LIST 中的每个事务执行 UNDO 操作
- 对 REDO-LIST 中的每个事务执行 REDO 操作
数据库镜像 (不考)
介质故障是对系统影响最为严重的一种故障,严重影响数据库的可用性
- 介质故障恢复比较费时
- 为预防介质故障,数据库管理员必须周期性地转储数据库
提高数据库可用性的解决方案
- 数据库镜像(Mirror)
数据库镜像
- 数据库管理系统自动把整个数据库或其中的关键数据复制到另一个磁盘上
- 数据库管理系统自动保证镜像数据与主数据的一致性
- 每当主数据库更新时,数据库管理系统自动把更新后的数据复制过去
出现介质故障时
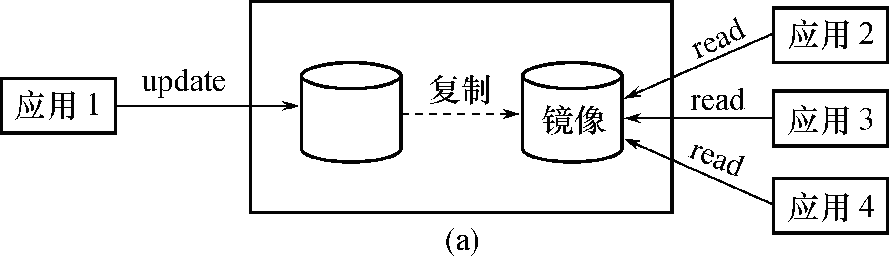
- 可由镜像磁盘继续提供使用
- 同时数据库管理系统自动利用镜像磁盘数据进行数据库的恢复
- 不需要关闭系统和重装数据库副本
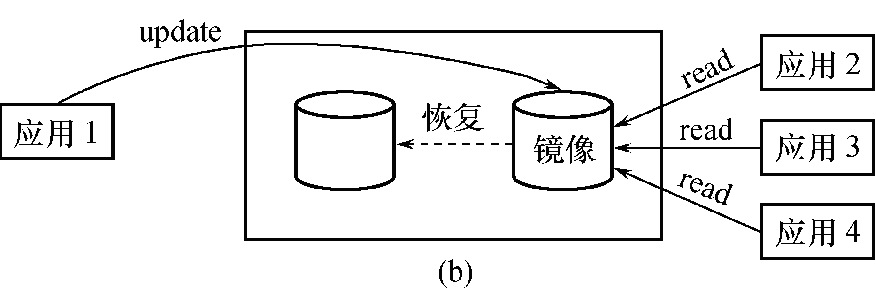
没有出现故障时
- 可用于并发操作.
- 一个用户对数据加排他锁修改数据,其他用户可以读镜像数据库上的数据,而不必等待该用户释放锁
第十一章、并发控制 (重点)
多用户数据库系统
- 允许多个用户同时使用的数据库系统,例如:
- 飞机订票数据库系统
- 银行数据库系统
- 他们的特点是在同一时刻的并发事务达到数百上千
多事务执行方式
-
事务串行
- 每一时刻只有一个事务在运行,其他事务必须等待上一个事务结束
- 不能充分利用系统资源,不能发挥数据库共享资源的特点

-
交叉并发方式
- 在单机处理机系统中,事务的并行执行是这些并行事务的并行操作轮流交叉运行
- 单处理机系统中的并行事务并没有真正地并行运行,但能够减少处理机的空闲时间,提高系统的效率
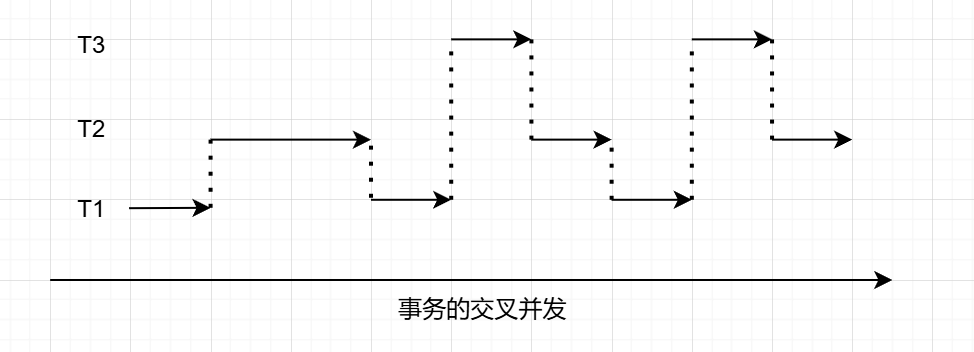
-
事务的同时并发
- 多处理机系统中,每个处理机可以运行一个事务,多个处理机可以同时运行多个事务,实现多个事务真正的并行运行
- 最理想的并发方式,但受制于硬件环境
- 更复杂的并发方式机制(需要多机同步的分布式锁)
所以我们下面讨论的数据库系统并发控制技术是以单处理机系统为基础的
事务并发执行带来的问题 (重要)
- 会产生多个事务同时存取同一数据的情况
- 可能会存取和存储不正确的数据,破坏事务隔离性和数据库的一致性
数据库管理系统必须提供并发控制机制,并发控制机制是衡量一个数据库管理系统性能的重要标志之一
并发控制概述
- 事务是并发控制的基本单位
- 并发控制机制的任务
- 对并发操作进行正确调度
- 保证事务的隔离性
- 保证数据库的一致性
并发操作带来数据的不一致性实例
[例 11.1] 飞机订票系统中的一个活动序列
-
① 甲售票点(事务 T1)读出某航班的机票余额 A,设 A = 16;
-
② 乙售票点(事务 T2)读出同一航班的机票余额 A,也为 16;
-
③ 甲售票点卖出一张机票,修改余额 A←A-1,所以 A 为 15,把 A 写回数据库;
-
④ 乙售票点也卖出一张机票,修改余额 A←A-1,所以 A 为 15,把 A 写回数据库
-
结果明明卖出两张机票,数据库中机票余额只减少 1
-
这种情况称为数据库的不一致性,是由并发操作引起的。
-
在并发操作情况下,对 T1、T2 两个事务的操作序列的调度是随机的。
-
若按上面的调度序列执行,T1 事务的修改就被丢失。
- 原因:第 4 步中 T2 事务修改 A 并写回后覆盖了 T1 事务的修改
并发操作带来的数据不一致性 (重要)
- 丢失修改(Lost Update)
- 不可重复读(Non-repeatable Read)
- 读“脏”数据(Dirty Read)
记号 R(x): 读数据 xW(x): 写数据 x
丢失修改
两个事务 T1 和 T2 读入同一数据并修改,T2 的提交结果破坏了 T1 提交的结果,导致 T1 的修改被丢失。
上面飞机订票例子就属此类

不可重复读
不可重复读是指事务 T1 读取数据后,事务 T2 执行更新操作,使 T1 无法再现前一次读取结果。
不可重复读包括三种情况:
-
事务 T1 读取某一数据后,事务 T2 对其做了修改,当事务 T1 再次读该数据时,得到与前一次不同的值
例如:
T1 T2 ① R(A)= 50 R(B)= 100 求和 = 150 ② R(B)= 100 B←B*2 W(B)= 200 ③ R(A)= 50 R(B)= 200 求和 = 250 (验算不对) -
事务 T1 按一定条件从数据库中读取了某些数据记录后, 事务 T2 删除了其中部分记录 ,当 T1 再次按相同条件读取数据时,发现某些记录神秘地消失了。
-
事务 T1 按一定条件从数据库中读取某些数据记录后, 事务 T2 插入了一些记录 ,当 T1 再次按相同条件读取数据时,发现多了一些记录。
后两种不可重复读有时也称为 幻影现象(Phantom Row)
读“脏”数据(脏读)
读“脏”数据是指:
- 事务 T1 修改某一数据,并将其写回磁盘
- 事务 T2 读取同一数据后,T1 由于某种原因被撤销
- 这时 T1 已修改过的数据恢复原值,T2 读到的数据就与数据库中的数据不一致
- T2 读到的数据就为“脏”数据,即不正确的数据
| T1 | T2 |
|---|---|
| ① R©= 100 | |
| C←C*2 | |
| W©= 200 | |
| ② | R©= 200 |
| ③ ROLLBACK | |
| C 恢复为 100 |
- 在 ② 处 T2 读到了脏数据,因为下面 ③ 处 C 被撤销修改了(脏读一定伴随回滚)
数据不一致性: 由于并发操作破坏了事务的隔离性
并发控制就是要用 正确的方式调度并发操作 ,使一个用户事务的执行不受其他事务的干扰,从而避免造成数据的不一致性
对数据库的应用有时允许某些不一致性,例如有些统计工作涉及数据量很大,读到一些“脏”数据对统计精度没什么影响,可以降低对一致性的要求以减少系统开销
并发控制的主要技术
- 封锁(Locking)
- 时间戳(Timestamp)
- 乐观控制法
- 多版本并发控制(MVCC)
封锁
什么是封锁
封锁就是事务 T 在对某个数据对象(例如表、记录等)操作之前,先向系统发出请求,对其加锁。
加锁后事务 T 就对该数据对象有了一定的控制,在事务 T 释放它的锁之前,其它的事务不能更新此数据对象。
封锁是实现并发控制的一个非常重要的技术
基本的封锁类型
一个事务对某个数据对象加锁后究竟拥有什么样的控制由封锁的类型决定。
- 排它锁(Exclusive Locks,简记为 X 锁)
- 共享锁(Share Locks,简记为 S 锁)
排它锁:
-
排它锁又称为写锁
-
若事务 T 对数据对象 A 加上 X 锁,则只允许 T 读取和修改 A, 其它 任何事务都 不能 再对 A 加任何类型的锁 ,直到 T 释放 A 上的锁
-
保证其他事务在 T 释放 A 上的锁之前不能再读取和修改 A
加了排它锁,其他事务就完全无法访问,也不能再加锁
共享锁:
-
共享锁又称为读锁
-
若事务 T 对数据对象 A 加上 S 锁,则 事务 T 可以读 A 但 不能修改 A , 其它事务只能再对 A 加 S 锁,而不能加 X 锁 ,直到 T 释放 A 上的 S 锁
-
保证其他事务可以读 A,但在 T 释放 A 上的 S 锁之前不能对 A 做任何修改
加了共享锁,任何事务都只读这个数据,但可以再加共享锁
锁的相容矩阵:
| T 2 /T 1 | X | S | – |
|---|---|---|---|
| X | N | N | Y |
| S | N | Y | Y |
| – | Y | Y | Y |
Y = Yes,相容的请求
N = No,不相容的请求
封锁协议 (重点)
什么是封锁协议?
- 在运用 X 锁和 S 锁对数据对象加锁时,需要 约定一些规则 ,这些规则为 封锁协议(Locking Protocol)。
- 何时申请 X 锁或 S 锁
- 持锁时间
- 何时释放
- 对封锁方式规定不同的规则,就形成了各种不同的封锁协议,它们分别在不同的程度上为并发操作的正确调度提供一定的保证。
三级封锁协议
-
一级封锁协议:
- 在事务 T 修改数据 R 之前必须先对其加 X 锁, 直到事务结束 才释放。
- 一级封锁协议可 防止丢失修改 ,并 保证事务 T 是可恢复 的。
- 在一级封锁协议中,如果 仅仅是读数据 不对其进行修改,是 不需要加锁 的,所以它 不能保证可重复读和不读“脏”数据。
总结:写 之前 加 写锁 , 读不管 了, 事务结束释放写锁
T1 T2 ① Xlock A ② R(A)= 16 Xlock A ③ A←A-1 等待 W(A)= 15 等待 Commit 等待 Unlock A 等待 ④ 获得 Xlock A R(A)= 15 A←A-1 ⑤ W(A)= 14 Commit Unlock A -
二级封锁协议:
- 一级封锁协议加上事务 T 在 读 取数据 R 之前 必须先对其 加 S 锁 , 读完后即可释放 S 锁 。
- 二级封锁协议可以 防止丢失修改和读“脏”数据 。
- 在二级封锁协议中,由于读完数据后即可释放 S 锁,所以它 不能保证可重复读 。
总结:在一的基础上, 读之前加读锁,读完马上释放
T1 T2 ① Xlock C R©= 100 C←C*2 W©= 200 ② Slock C 等待 ③ROLLBACK 等待 (C 恢复为 100) 等待 Unlock C 等待 ④ 获得 Slock C R©= 100 ⑤ Commit C Unlock C -
三级封锁协议:
- 一级封锁协议加上事务 T 在读取数据 R 之前必须先对其加 S 锁,直到事务结束才释放。
- 三级封锁协议可 防止丢失修改、读脏数据和不可重复读 。
总结:在二的基础上, 把读锁延迟到事务结束再释放
T1 T2 ① Slock A Slock B R(A)= 50 R(B)= 100 求和 = 150 ② Xlock B 等待 ③ R(A)= 50 等待 R(B)= 100 等待 求和 = 150 等待 Commit 等待 Unlock A 等待 Unlock B 等待 ④ 获得 XlockB R(B)= 100 B←B*2 ⑤ W(B)= 200 Commit Unlock B
三级协议的主要区别
- 什么操作需要申请封锁以及何时释放锁(即持锁时间)
不同的封锁协议使事务达到的一致性级别不同
- 封锁协议级别越高,一致性程度越高
| X 锁 | S 锁 | 一致性保证 | |||||
|---|---|---|---|---|---|---|---|
| 操作结束释放 | 事务结束释放 | 操作结束释放 | 事务结束释放 | 不丢失 修改 | 不读“脏”数据 | 可重复 读 | |
| 一级封锁协议 | √ | √ | |||||
| 二级封锁协议 | √ | √ | √ | √ | |||
| 三级封锁协议 | √ | √ | √ | √ | √ |
活锁和死锁
活锁
例子:
- 事务 T1 封锁了数据 R
- 事务 T2 又请求封锁 R,于是 T2 等待。
- T3 也请求封锁 R,当 T1 释放了 R 上的封锁之后系统首先批准了 T3 的请求,T2 仍然等待。
- T4 又请求封锁 R,当 T3 释放了 R 上的封锁之后系统又批准了 T4 的请求……
- T2 有可能永远等待,这就是活锁的情形
总结:事务太多, 有一个事务总是等不到执行 ,这个事务就活锁了(活生生锁上了)
| T1 | T2 | T3 | T4 |
|---|---|---|---|
| Lock R | ••• | ••• | • • • |
| • | Lock R | ||
| • | 等待 | Lock R | |
| • | 等待 | • | Lock R |
| Unlock R | 等待 | • | 等待 |
| 等待 | Lock R | 等待 | |
| • | 等待 | • | 等待 |
| • | 等待 | Unlock | 等待 |
| • | 等待 | • | Lock R |
| 等待 | • | •• |
如何避免?
- 采用先来先服务的策略(使用队列,事务先进先出)
- 当多个事务请求封锁同一数据对象时
- 按请求封锁的先后次序对这些事务排队
- 该数据对象上的锁一旦释放,首先批准申请队列中第一个事务获得锁
死锁
例子:
- 事务 T1 封锁了数据 R1
- T2 封锁了数据 R2
- T1 又请求封锁 R2,因 T2 已封锁了 R2,于是 T1 等待 T2 释放 R2 上的锁
- 接着 T2 又申请封锁 R1,因 T1 已封锁了 R1,T2 也只能等待 T1 释放 R1 上的锁
- 这样 T1 在等待 T2,而 T2 又在等待 T1,T1 和 T2 两个事务永远不能结束,形成 死锁
总结:两个或多个事务, 都想改相互的数据 ,导致 你等我-我等你 ,就死锁了
| T1 | T2 |
|---|---|
| Lock R1 | ••• |
| • | Lock R2 |
| •• | •• |
| Lock R2 | • |
| 等待 | |
| 等待 | |
| 等待 | Lock R1 |
| 等待 | 等待 |
| 等待 | 等待 |
| ••• |
解决死锁的两类方法:
预防
产生死锁的原因是两个或多个事务都已封锁了一些数据对象,然后又都请求对已为其他事务封锁的数据对象加锁,从而出现死等待。
预防死锁的发生就是要破坏产生死锁的条件
-
一次封锁法
这一次事务中你要用到的数据,我要求你在开始的时候全部一起上锁
这样会导致并发性下降,而且难以实现(数据经常变化导致无法确定事先要封锁的对象)
-
顺序封锁法
顺序封锁法是预先对数据对象规定一个封锁顺序,所有事务都按这个顺序实行封锁。
但是这会导致维护顺序的成本很高(数据量太大),还有难以实现(无法事先确定要封锁的对象)
在操作系统中广为采用的 预防 死锁的策略 并不太适合 数据库 的特点
诊断
-
超时法
如果一个事务的等待时间 超过了规定的时限 ,就认为发生了 死锁
这样实现起来非常简单,但是可能 导致长事务被假定为死锁 ,而且 真正的死锁不能第一时间发现
总结:等久了就当你死锁
-
等待图法
用事务等待图动态反映所有事务的等待情况
- 事务等待图是一个有向图 G =(T,U)
- T 为结点的集合,每个结点表示正运行的事务
- U 为边的集合,每条边表示事务等待的情况
- 若 T1 等待 T2,则 T1,T2 之间划一条有向边,从 T1 指向 T2
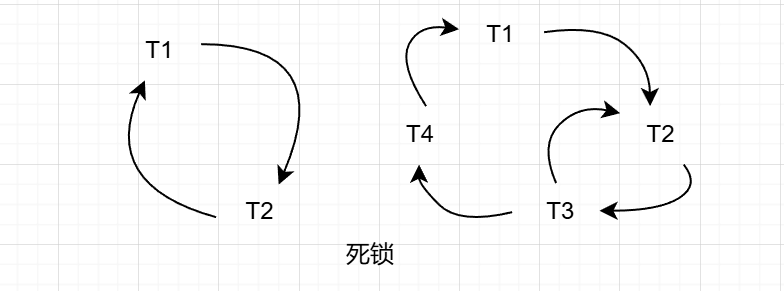
并发控制子系统周期性地(比如每隔数秒)生成事务等待图,检测事务。如果发现图中存在回路,则表示系统中出现了死锁。
总结:谁等谁就从谁指到谁,如果形成环就死锁了
解除死锁
- 选择一个处理死锁代价最小的事务,将其撤消
- 释放此事务持有的所有的锁,使其它事务能继续运行下去
总结:死锁的事务中谁持有的 锁最少 ,就把这个事务 回滚 ,当他没发生过
并发调度的可串行性 (必考)
数据库管理系统对并发事务不同的调度可能会产生不同的结果
串行调度是正确的
执行结果等价于串行调度的调度也是正确的,称为可串行化调度
简单来说:并发调度的顺序可能导致结果不同,但是串行执行的结果肯定是对的,如果并发和串行的执行结果一样,那么这个并发就可串行化。
可串行化调度
可串行化(Serializable)调度
- 多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同
可串行性(Serializability)
- 是并发事务正确调度的准则
- 一个给定的并发调度,当且仅当它是可串行化的,才认为是正确调度
例:
-
现在有两个事务,分别包含下列操作:
- 事务 T1:读 B;A = B+1;写回 A
- 事务 T2:读 A;B = A+1;写回 B
-
串行执行结果:
- 先 T1 后 T2:A = 3,B = 4
- 先 T2 后 T1:B = 3,A = 4
这两种结果都是正确的
-
错误的调度结果:
T1 T2 Slock B Y = R(B)= 2 Slock A X = R(A)= 2 Unlock B Unlock A Xlock A A = Y+1 = 3 W(A) Xlock B B = X+1 = 3 W(B) Unlock A Unlock B 执行结果为:A = 3,B = 3
显然这个结果和任何的串行调度结果都不一样,肯定是错的 -
正确的调度结果
T1 T2 Slock B Y = R(B)= 2 Unlock B Xlock A Slock A A = Y+1 = 3 等待 W(A) 等待 Unlock A 等待 X = R(A)= 3 Unlock A Xlock B B = X+1 = 4 W(B) Unlock B 执行结果为:A = 3,B = 4
与串行调度的结果相同,是正确的
冲突可串行化调度
冲突:调度中一对连续的动作,它们满足:如果顺序交换,那么涉及的事务中至少一个事务的行为会发生改变。
有冲突的两个事务是不能交换次序的, 没有冲突的两个事务是可交换的
几种冲突的情况 (必考):
-
同一 事务的 任意 两个操作都是冲突的
ri(X); wi(X) wi(X); ri(Y)
-
不同事务 对 一个 元素的 两个写 操作是冲突的
wi(X), wj(Y)
-
不同事务 对 一个 元素的 读和写 操作是冲突的
wi(X), rj(X) ri(X), wk(X)
如果一个调度是冲突可串行化,那么一定是可串行化的调度,即一定是正确的调度
也就是说:一个调度中,你可以交换不冲突的操作,使其变成串行化操作(可串行化),那么称原调度的冲突可串行化

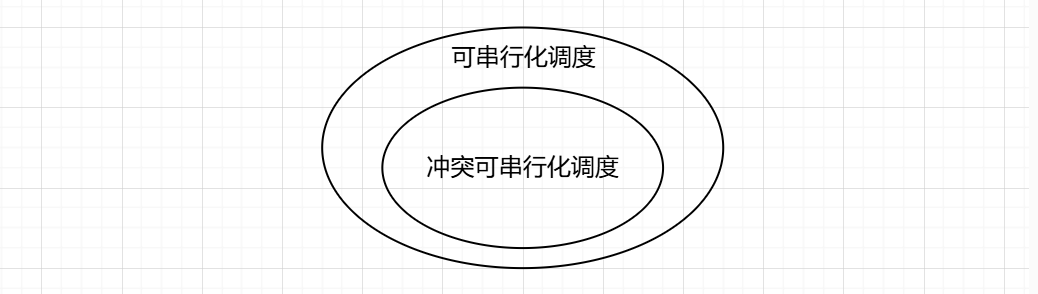
冲突可串行化 是 可串行化 的 充分不必要条件
可串行化调度: 指一个并发调度,其结果与某个事务串行执行的结果相同。这种调度确保了并发执行不会导致数据的不一致性,是并发控制的一个理想目标。
冲突可串行化: 是一种特定类型的可串行化调度,它通过检查事务操作之间的冲突来判断调度是否可串行化。具体来说,如果一个调度能够通过 交换相邻的非冲突操作 转换成一个串行调度,那么这个调度就是冲突可串行化的。
冲突可串行的判别算法
冲突图(Conflict Graph):通过构建冲突图来判定调度是否冲突可串行化。冲突图的无环性(即图是一个有向无环图,DAG)表明调度是冲突可串行化的。
输入
- 一组事务及其操作的调度。
输出
- 如果冲突图是无环图,则调度是冲突可串行化的;否则,调度不是冲突可串行化的。
步骤
-
标识事务和操作:
- 标识调度中涉及的所有事务和它们的操作。例如,假设有两个事务 (T1) 和 (T2),调度如下:
[ S = R1(A), W2(A), W1(B), R2(B) ]
- 标识调度中涉及的所有事务和它们的操作。例如,假设有两个事务 (T1) 和 (T2),调度如下:
-
构建节点:
- 为每个事务创建一个节点。例如,这里有两个事务 (T1) 和 (T2),因此冲突图中有两个节点:(T1) 和 (T2)。
-
识别冲突操作:
- 遍历调度中的操作,识别操作之间的冲突。冲突的条件是:
- 它们属于不同的事务。
- 它们访问相同的数据项。
- 至少有一个操作是写操作。
- 在上面的调度中,有以下冲突:
- (R1(A)) 和 (W2(A)) 冲突(读-写冲突)。
- (W1(B)) 和 (R2(B)) 冲突(写-读冲突)。
- 遍历调度中的操作,识别操作之间的冲突。冲突的条件是:
-
添加有向边:
- 根据冲突在节点之间添加有向边。如果操作 (O1) 在操作 (O2) 之前,并且 (O1) 与 (O2) 冲突,则添加一条从 (O1) 所属事务到 (O2) 所属事务的有向边。
- 例如,根据上面的冲突:
- 从 (T1) 到 (T2) 添加一条边(由于 (R1(A)) 与 (W2(A)) 冲突)。
- 从 (T2) 到 (T1) 添加一条边(由于 (W1(B)) 与 (R2(B)) 冲突)。
-
检测环:
- 检查构建的冲突图是否有环。如果图中存在环,说明调度不是冲突可串行化的;如果图是无环的(DAG),说明调度是冲突可串行化的。
- 环的检测可以使用深度优先搜索(DFS)或拓扑排序等算法。
示例
假设有如下调度:
[ S = R1(A), W2(A), W1(B), R2(B) ]
步骤 1:标识事务和操作
- 事务:(T1),(T2)
- 操作顺序:(R1(A), W2(A), W1(B), R2(B))
步骤 2:构建节点
- 节点:(T1),(T2)
步骤 3:识别冲突操作
- 冲突:(R1(A)) 和 (W2(A)),(W1(B)) 和 (R2(B))
步骤 4:添加有向边
- 边:(T1 \rightarrow T2)(由于 (R1(A)) 和 (W2(A)) 冲突)
- 边:(T2 \rightarrow T1)(由于 (W1(B)) 和 (R2(B)) 冲突)
步骤 5:检测环
- 图中有环:(T1 \rightarrow T2 \rightarrow T1)
- 由于存在环,调度 (S) 不是冲突可串行化的。
举例说明
假设有两个事务 (T1) 和 (T2):
- (T1) 执行操作 (R(A), W(B))
- (T2) 执行操作 (W(A), R(B))
考虑以下调度 (S):
[ S = R1(A), W2(A), W1(B), R2(B) ]
我们可以构建冲突图:
- (T1) 的 (R(A)) 和 (T2) 的 (W(A)) 冲突,产生边 (T1 \rightarrow T2)
- (T1) 的 (W(B)) 和 (T2) 的 (R(B)) 冲突,产生边 (T2 \rightarrow T1)
冲突图有环 (T1 \rightarrow T2 \rightarrow T1),因此 (S) 不是冲突可串行化的。
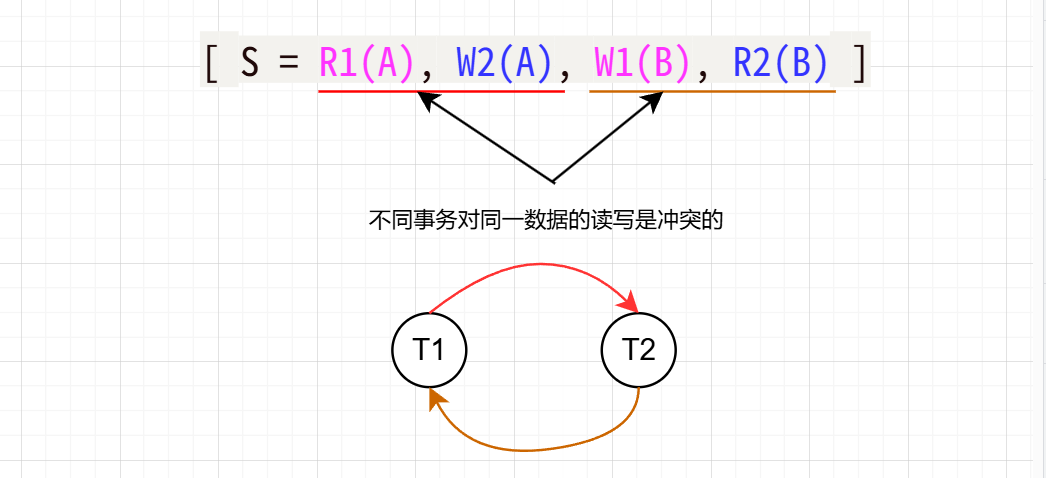
两端锁协议
两段锁协议(Two-Phase Locking, 2PL)是数据库管理系统中用于确保事务调度可串行化的一种并发控制协议。通过遵循两段锁协议,事务可以保证在并发执行时不会导致数据不一致,从而实现可串行化。
两段锁协议的定义
两段锁协议将事务的锁定操作划分为两个阶段:
-
扩展阶段(Growing Phase):
- 在这个阶段,事务可以获取锁,但不能释放锁。
- 事务可以在需要时锁定任意数据项。
-
收缩阶段(Shrinking Phase):
- 在这个阶段,事务可以释放锁,但不能再获取新的锁。
- 一旦事务开始释放锁,就不能再获取任何新的锁。
工作原理
-
锁的获取和释放:
- 事务在执行过程中,当需要读或写某个数据项时,首先必须获取相应的锁。
- 在扩展阶段,事务不断获取所需的锁。
- 一旦事务释放第一个锁,进入收缩阶段,此后只能释放锁而不能再获取新的锁。
-
保持可串行化:
- 通过严格遵守两段锁协议,可以防止循环等待和死锁,从而保证调度的可串行化。
- 该协议确保所有锁在事务结束前已经获取,并在事务提交或回滚时释放,从而维持数据的一致性。
示例
假设有两个事务 (T1) 和 (T2):
- (T1) 需要读写数据项 A 和 B
- (T2) 需要读写数据项 B 和 C
按照两段锁协议,它们的执行过程可能如下:
-
事务 (T1):
- 获取 A 的读锁。
- 获取 B 的写锁。
- 执行读写操作。
- 释放 A 和 B 的锁。
-
事务 (T2):
- 获取 B 的读锁(必须等待 (T1) 释放 B 的写锁)。
- 获取 C 的写锁。
- 执行读写操作。
- 释放 B 和 C 的锁。
在这个示例中,尽管事务 (T1) 和 (T2) 可能会并发执行,但由于两段锁协议的约束,它们的执行结果等同于某种顺序的串行执行,从而保证了可串行化。
总结
两段锁协议通过将锁定操作分为扩展阶段和收缩阶段,确保了事务的执行调度是可串行化的。其主要特点是:
- 扩展阶段:事务可以获取锁,但不能释放锁。
- 收缩阶段:事务可以释放锁,但不能再获取新的锁。
这种分阶段的锁操作保证了以下性质:
- 没有锁操作交错:一个事务在开始释放锁之前,已经获取了它需要的所有锁。换句话说,在事务的扩展阶段结束之前,所有锁都已经获取完毕;在事务的收缩阶段开始之后,所有锁都只能被释放而不能再获取新的锁。
- 无循环等待:由于事务在释放第一个锁之后不再获取任何新的锁,因此不存在循环等待的情况。这避免了死锁的发生。
两段锁协议通过上述性质 确保调度是可串行化 的,其原理可以通过以下几点来理解:
- 顺序的锁释放:在扩展阶段,每个事务获取锁的顺序和时间点是固定的;在收缩阶段,每个事务释放锁的顺序和时间点也是固定的。这种固定的锁获取和释放顺序,实际上相当于将并发执行的事务安排成某种串行顺序。
- 事务间的依赖关系:如果一个事务需要等待另一个事务释放锁,那么它的操作就必须在另一个事务的操作之后进行。这种等待关系形成了事务之间的依赖关系,确保了操作顺序的正确性。
- 冲突图无环:在两段锁协议下,如果构建冲突图(即节点表示事务,边表示事务之间的冲突关系),由于没有循环等待,冲突图必定是无环的。无环的冲突图意味着存在一个线性顺序,使得调度等价于按该顺序串行执行事务。
例:
| 事务 T1 | 事务 T2 |
|---|---|
| Slock A | |
| R(A)= 260 | |
| Slock C | |
| R©= 300 | |
| Xlock A | |
| W(A)= 160 | |
| Xlock C | |
| W©= 250 | |
| Slock A | |
| Slock B | 等待 |
| R(B)= 1000 | 等待 |
| Xlock B | 等待 |
| W(B)= 1100 | 等待 |
| Unlock A | 等待 |
| R(A)= 160 | |
| Xlock A | |
| Unlock B | |
| W(A)= 210 | |
| Unlock C |
封锁的粒度
封锁粒度(Lock Granularity)是数据库并发控制中的一个重要概念,指的是数据库管理系统(DBMS)在进行并发控制时对数据加锁的粒度或单位。封锁粒度的选择对数据库系统的性能和并发性有很大的影响。
选择封锁粒度时,需要在封锁开销和并发度之间进行权衡。不同的封锁粒度适用于不同的应用场景,以确保系统在保持高并发性的同时,尽量减少锁管理的开销。以下是适当选择封锁粒度的具体指导:
1. 需要处理多个关系的大量元组的用户事务
以数据库为封锁单位
- 封锁开销:最低,因为只需要管理一个锁。
- 并发度:最低,因为整个数据库被锁定,阻止了所有其他事务对数据库的访问。
- 适用场景:适用于大规模批处理操作,如数据库备份、全库扫描等场景。这种情况下,锁住整个数据库可以避免复杂的锁管理,同时确保数据的一致性。
2. 需要处理大量元组的用户事务
以关系(表)为封锁单元
- 封锁开销:较低,因为锁定单个表相对于页级或行级锁开销更小。
- 并发度:中等,因为多个事务可以同时访问不同的表,但对同一个表的并发访问会受到限制。
- 适用场景:适用于需要对单个表进行大量操作的事务,如批量插入、更新或删除操作。这种情况下,锁住整个表可以简化锁管理,减少锁争用,同时提供适度的并发性。
3. 只处理少量元组的用户事务
以元组(行)为封锁单位
- 封锁开销:最高,因为需要管理大量的锁。
- 并发度:最高,因为多个事务可以同时访问同一个表中的不同行。
- 适用场景:适用于细粒度操作,如频繁的插入、更新或删除少量记录的事务。这种情况下,行级锁提供了最高的并发性,允许多个事务并行操作同一个表的不同行,最大限度地利用数据库资源。
具体场景示例
场景 1:批处理操作
- 操作描述:每晚进行全库数据备份。
- 封锁粒度选择:数据库级锁。
- 原因:全库备份需要一致性,锁住整个数据库避免了复杂的锁管理,且备份操作通常在非高峰期进行,对并发度要求不高。
场景 2:表级批量更新
- 操作描述:每天更新数百万条订单记录。
- 封锁粒度选择:表级锁。
- 原因:表级锁可以简化大量记录更新的锁管理,同时提供比数据库级锁更高的并发性,允许其他事务访问不相关的表。
场景 3:在线交易处理
- 操作描述:用户频繁插入、更新少量订单记录。
- 封锁粒度选择:行级锁。
- 原因:行级锁提供最高的并发性,允许多个用户同时操作不同订单记录,提高系统的吞吐量和响应速度。
多粒度树是一种用来表示和管理多级封锁粒度的数据结构,通常用于数据库管理系统中的并发控制。在多粒度树中,根节点代表整个数据库,表示最大的数据粒度,而叶子节点则表示最小的数据粒度,例如表中的行或者字段。这种树形结构可以帮助系统有效地管理不同级别的锁,并确保并发操作的正确性和性能。
多粒度树的结构
在多粒度树中,每个节点代表一个锁定的粒度,可以是数据库、表、页或行。树的结构如下:
- 根节点(Root Node):表示整个数据库,是最大的数据粒度。通常使用数据库级锁。
- 内部节点(Internal Nodes):表示表或页,介于根节点和叶子节点之间的中间粒度。
- 叶子节点(Leaf Nodes):表示最小的数据粒度,例如表中的行或字段。通常使用行级锁或字段级锁。
示例
假设有一个数据库包含两个表 AAA 和 BBB,每个表分别包含多个页,每页包含多行。则可以构建如下的多粒度树:
-
根节点:整个数据库
-
内部节点
AAA
:表
AAA
-
叶子节点
A1A1A1
:表
AAA
的第一个页
- 叶子节点 A11A11A11:表 AAA 第一个页的第一行
- 叶子节点 A12A12A12:表 AAA 第一个页的第二行
- …
-
叶子节点 A2A2A2:表 AAA 的第二个页
-
…
-
-
内部节点
BBB
:表
BBB
- 叶子节点 B1B1B1:表 BBB 的第一个页
- 叶子节点 B2B2B2:表 BBB 的第二个页
- …
-
在这个示例中,根节点表示整个数据库,内部节点表示不同的表,叶子节点表示表中的具体页或行。每个节点可以根据需要使用适当的封锁粒度,例如表级锁、页级锁或行级锁。
多粒度树的优点
- 灵活性:多粒度树允许数据库系统根据具体情况选择合适的封锁粒度,从而在保证数据一致性的前提下最大限度地提高并发性能。
- 管理复杂度降低:通过树形结构,可以清晰地表示和管理不同级别的锁,减少了封锁管理的复杂性。
- 效率:根据需要进行锁定和解锁操作,避免了不必要的锁争用和性能损失。
在多粒度封锁中一个数据对象可能以两种方式封锁:显式封锁和隐式封锁
显式封锁: 直接加到数据对象上的封锁
隐式封锁: 是该数据对象没有独立加锁,是由于其上级结点加锁而使该数据对象加上了锁
显式封锁和隐式封锁的效果是一样的
对某个数据对象加锁,系统要检查:
- 该数据对象
- 有无显式封锁与之冲突
- 所有上级结点
- 检查本事务的显式封锁是否与该数据对象上的隐式封锁冲突:(由上级结点已加的封锁造成的)
- 所有下级结点
- 看上面的显式封锁是否与本事务的隐式封锁(将加到下级结点的封锁)冲突
意向锁
意向锁(Intention Lock)是数据库管理系统中用来提高并发控制效率的一种技术。引入意向锁的主要目的是为了在多粒度锁定的环境中,有效地减少锁的冲突和提升系统性能。
目的和作用
- 降低锁冲突:
- 在数据库系统中,锁的粒度可以从粗到细,比如数据库级、表级、页级和行级锁。当一个事务在更细粒度上请求锁时,需要先获取该粒度所处的更粗粒度上的意向锁。这样可以通过意向锁来指示其他事务该事务在更细粒度上有锁的意图,从而减少不必要的锁冲突。
- 提高并发性:
- 意向锁允许多个事务并发地操作同一个数据对象的不同粒度。例如,一个事务可能在行级别请求排他锁,而另一个事务可以在表级别请求共享锁,这两个事务之间的意向锁可以协调它们之间的并发操作,避免互斥和死锁。
- 简化锁管理:
- 使用意向锁可以简化数据库系统内部的锁管理机制。数据库管理系统可以根据意向锁的信息来判断是否需要进一步授予或拒绝更细粒度的锁请求,从而减少了对资源的竞争和管理开销。
- 避免死锁:
- 意向锁还可以帮助避免死锁的发生。通过意向锁,数据库管理系统可以预先检查事务对数据对象的锁请求是否会导致循环等待,从而在锁定资源之前就可以进行合理的调度和决策,避免死锁的发生。
意向锁类型
常见的意向锁类型包括:
- 意向共享锁(IS,Intention Shared Lock):表示事务打算在更细粒度上获取共享锁。
- 意向排他锁(IX,Intention Exclusive Lock):表示事务打算在更细粒度上获取排他锁。
- 共享意向排他锁(SIX,Shared and Intention Exclusive Lock):表示事务已经在粗粒度上持有共享锁,并希望在更细粒度上获取排他锁。
这些意向锁的引入使得数据库系统在并发控制中能够更有效地管理和调度锁资源,提高系统的性能和并发性。
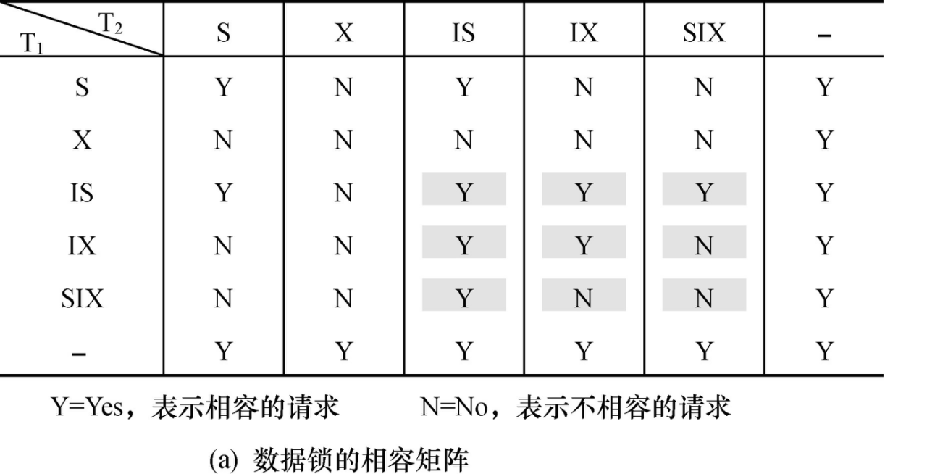
锁的强度
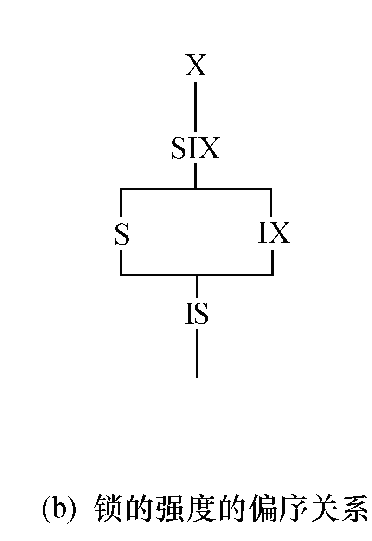
锁的强度是指它对其他锁的排斥程度
一个事务在申请封锁时以强锁代替弱锁是安全的,反之则不然
多粒度封锁结合意向锁的方法,通常按照自上而下的次序申请锁,按自下而上的次序释放锁,以确保有效的并发控制和减少死锁风险。
申请封锁的步骤(自上而下)
- 事务 T1 要对关系 R1 加 S 锁:
- 首先,事务 T1 需要申请对整个数据库的意向共享锁(IS 锁)。
- 检查数据库和 R1 是否已加了不相容的锁(X 或 IX):
- 在获得数据库的 IS 锁后,事务 T1 需要检查数据库和关系 R1 是否已经被其他事务加了不相容的锁,如排他锁(X 锁)或者意向排他锁(IX 锁)。
- 如果数据库或 R1 已经被其他事务加了排他锁(X 锁),则事务 T1 无法继续申请 S 锁,需要根据并发控制协议等待或者回滚。
- 如果数据库或 R1 已经被其他事务加了意向排他锁(IX 锁),则事务 T1 也无法继续申请 S 锁,因为意向排他锁表明可能有事务打算在更细粒度上申请排他锁。
- 申请关系 R1 的 S 锁:
- 如果前面的检查没有冲突,事务 T1 可以继续申请关系 R1 的共享锁(S 锁)。
释放封锁的步骤(自下而上)
- 事务 T1 完成对 R1 的操作,准备释放 S 锁:
- 首先,事务 T1 需要释放关系 R1 的 S 锁。
- 释放数据库的 IS 锁:
- 在释放关系 R1 的 S 锁之后,事务 T1 需要释放数据库的意向共享锁(IS 锁)。
- 这样做可以减少锁的持有时间,允许其他事务在更细粒度上进行操作,提高系统的并发性能。
例子说明
假设事务 T1 要对关系 R1 加 S 锁,按照上述方法操作:
- 申请封锁过程:
- T1 首先申请数据库级的 IS 锁。
- 检查数据库和 R1 是否已加了不相容的锁(X 或 IX)。
- 如果检查通过,T1 继续申请 R1 的 S 锁。
- 释放封锁过程:
- T1 完成了对 R1 的操作,释放 R1 的 S 锁。
- 然后释放数据库级的 IS 锁。