
更优雅的多表查询
数据库设计原则
三大范式:
在数据库设计中,范式是一种指导和规范数据库设计的原则,旨在减少数据冗余、维护数据一致性和提高数据结构的合理性。遵循范式可以确保数据库具有良好的性能、可扩展性和维护性。本文将介绍数据库设计范式的基本概念、为什么需要遵循它们,以及如何应用这些原则来设计数据库。
一、范式的基本概念
范式是在关系型数据库设计中定义数据库结构的一种方式。它基于函数依赖和多值依赖的概念,确保数据表中的数据满足一定的组织和结构要求。范式可以分为不同的级别,从低级到高级依次为:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、BCNF、第四范式(4NF)等。每个级别都要求满足特定的条件,以消除数据冗余、维护数据一致性和提高数据结构的合理性。
二、为什么需要遵循范式
遵循范式有很多好处。首先,它有助于减少数据冗余,从而节省存储空间和提高数据检索效率。其次,它有助于维护数据一致性,避免数据不一致和数据冲突的问题。此外,遵循范式还可以提高数据结构的合理性和可维护性,使数据库设计更加规范和易于理解。
三、如何应用范式原则设计数据库
- 第一范式(1NF):确保每个列都是不可分割的最小单元,即原子性。这意味着每个字段都只包含一个值,没有重复的组或记录。
- 第二范式(2NF):在1NF的基础上,消除部分依赖。这意味着将数据表按照关键字段进行分解,以消除非键字段对键的部分依赖。这样可以进一步减少数据冗余和提高数据结构的合理性。
- 第三范式(3NF):在2NF的基础上,消除传递依赖。这意味着将数据表按照非键字段进行分解,以消除一个非键字段对另一个非键字段的传递依赖。这样可以进一步减少数据冗余和提高数据结构的合理性。
- BCNF:在3NF的基础上,消除多值依赖和连接依赖。这意味着将数据表按照函数依赖进行分解,以消除多值依赖和连接依赖。这样可以进一步减少数据冗余和提高数据结构的合理性。
- 第四范式(4NF):在BCNF的基础上,消除非平凡的函数依赖。这意味着将数据表按照非平凡的函数依赖进行分解,以消除非平凡的函数依赖。这样可以进一步减少数据冗余和提高数据结构的合理性。
在应用范式原则设计数据库时,需要仔细分析和评估每个级别的要求,并根据实际情况进行适当的分解和重组。同时,也需要考虑到性能和可维护性的因素,以确保数据库设计既合理又高效。
四、实践经验与建议
在实际应用中,遵循范式并不意味着每个数据表都必须严格满足每个级别的要求。有时候为了性能和可维护性的考虑,可能需要适当放宽某些要求。此外,对于某些复杂的数据关系和业务逻辑,可能需要在设计阶段就与业务人员和技术人员密切协作,共同讨论和确定最佳的设计方案。
总之,数据库设计范式是确保数据库结构合理、高效和可维护的重要原则。通过遵循这些原则并灵活运用它们,可以设计出高质量的数据库系统,从而为应用程序提供稳定、高效和可靠的数据支持。
数据关系
-
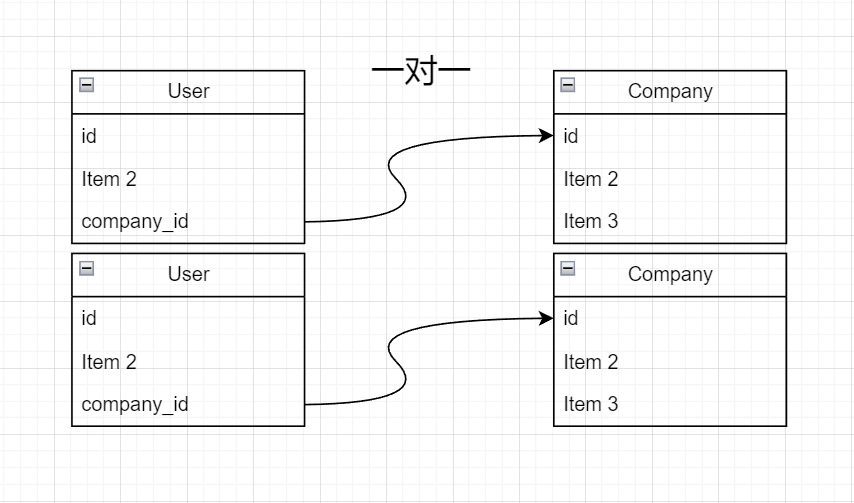
一对一:
-
-
{ "id": 111, "name": "qcqcqc", "companyId": 222, "company": { "id": 222, "name": "zust", "testId": 111, "test": { "id": 111, "name": "test" } } } -
在这个json数据中,一个user对应一个company,一个company对应一个test
-
-
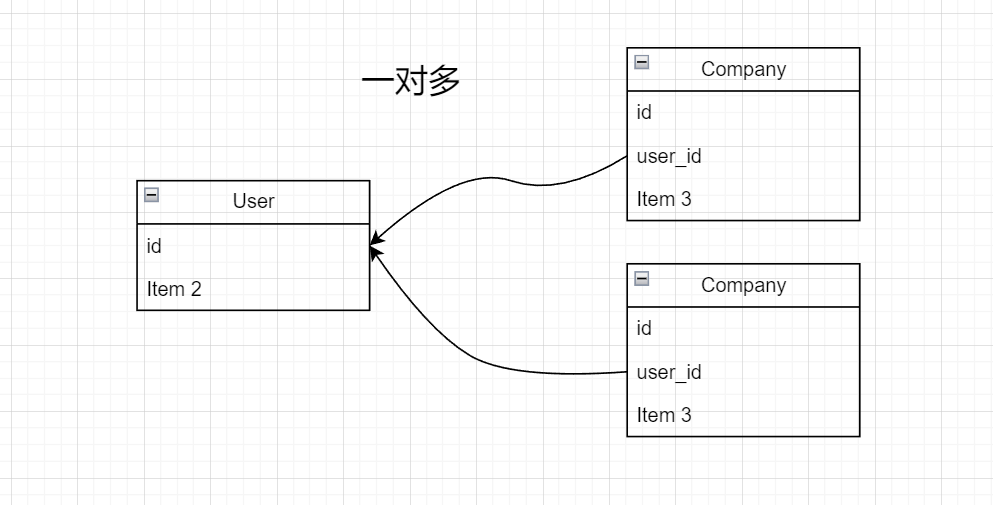
一对多
-
-
{ "id": 111, "name": "qcqcqc", "companyId": 222, "company": { "id": 222, "name": "zust", "tests": [ { "id": 555, "name": "test3", "companyId": 222 }, { "id": 666, "name": "test4", "companyId": 222 }, { "id": 777, "name": "test5", "companyId": 222 } ] } } -
在这个json数据中,companyId定义在test表内,一个company对应多个test
-
-
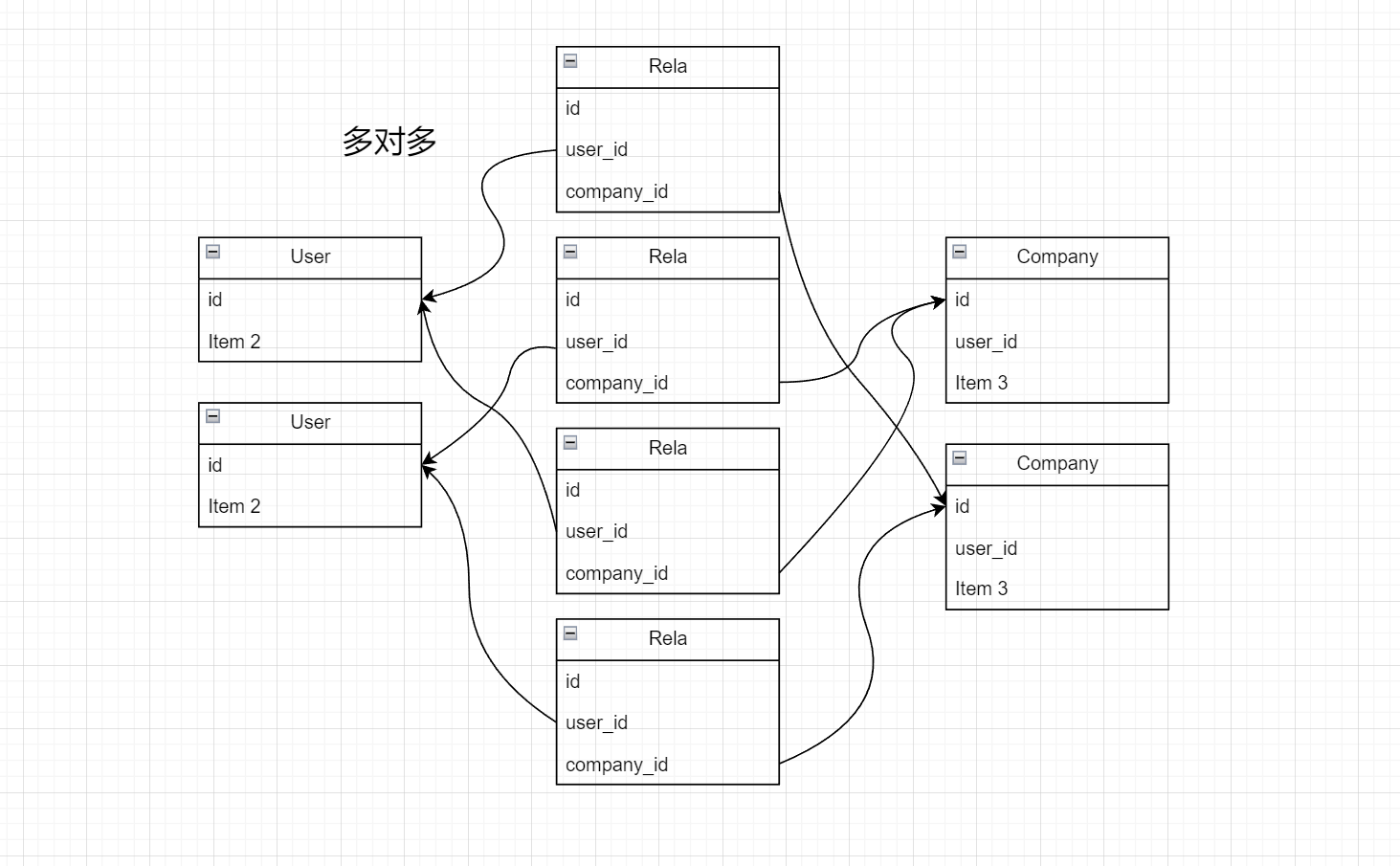
多对多
-
-
{ "id": 111, "name": "qcqcqc", "companyId": 222, "company": { "id": 222, "name": "zust", "testList": [ { "id": 111, "name": "test", }, { "id": 222, "name": "test2", }, { "id": 333, "name": "test3", } ], } } -
在这个json数据中,test内没有company的id,company内也没有test的id,而是通过关联表来查询二者关系并进行拼接
-
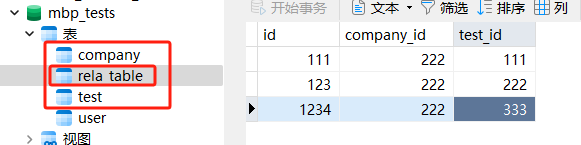
-
然后查询三张表来拼接数据
-
增强的Mybatisplus
在日常增删改查中,存在大量重复劳动,这种数据表拼接成最终数据的方式需要我们大量重复的编写查询和set代码,实在是繁琐
-
EnhanceService
-
实现了IService接口,实现与ServiceImpl相同的逻辑,但是增加了注解处理,可以使用我提供的注解来进行更加快速方便的查询
-
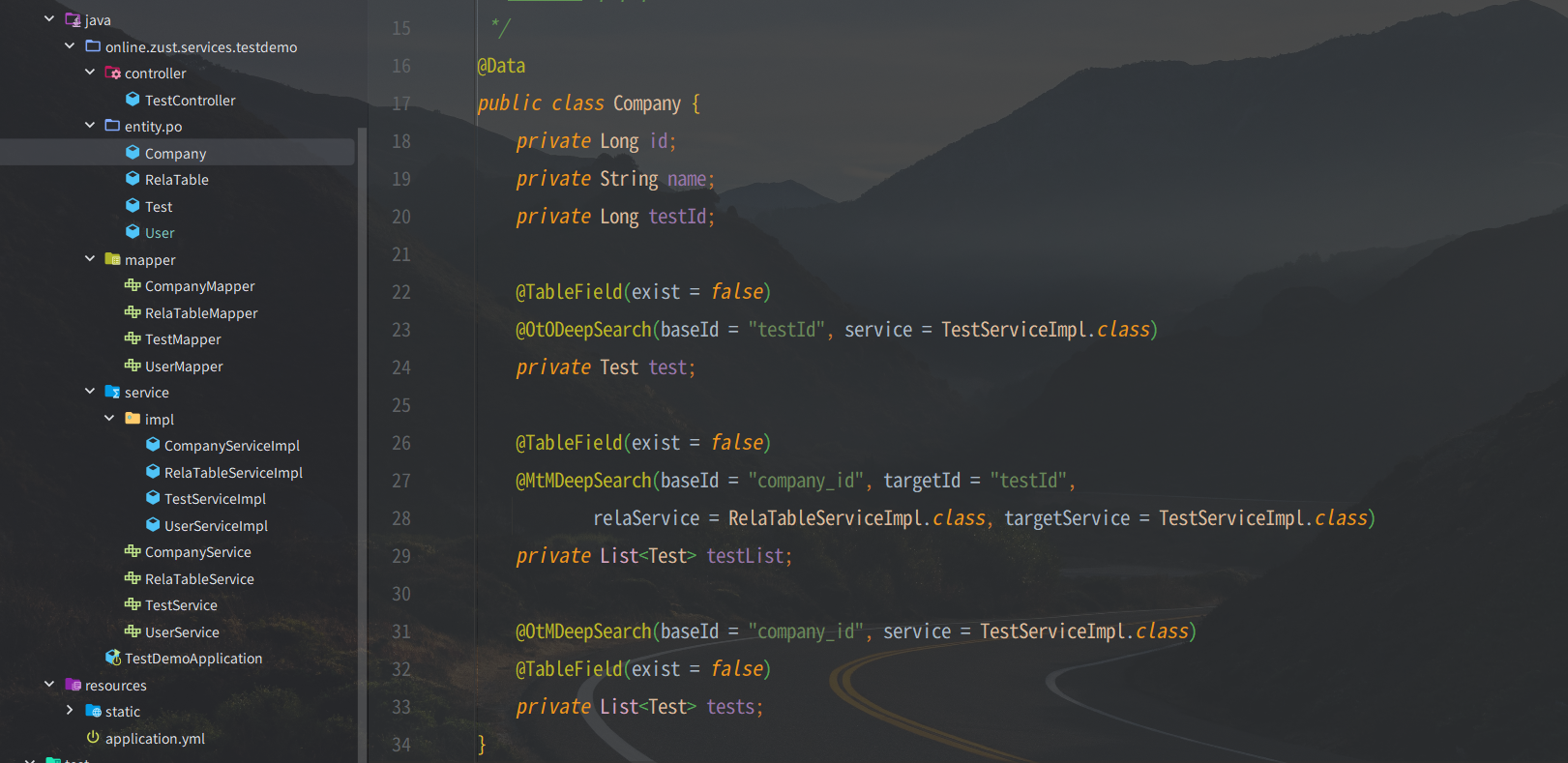
public T getDeepSearch(T entity) { if (entity == null) { return null; } Class<?> aClass = entity.getClass(); Field[] declaredFields = aClass.getDeclaredFields(); for (Field declaredField : declaredFields) { if (declaredField.isAnnotationPresent(OtODeepSearch.class)) { handleOtOAnnotation(entity, declaredField, aClass); } if (declaredField.isAnnotationPresent(MtMDeepSearch.class)) { handleMtMAnnotation(entity, declaredField, aClass); } if (declaredField.isAnnotationPresent(OtMDeepSearch.class)) { handleOtMAnnotation(entity, declaredField, aClass); } } return entity; }
一对一查询

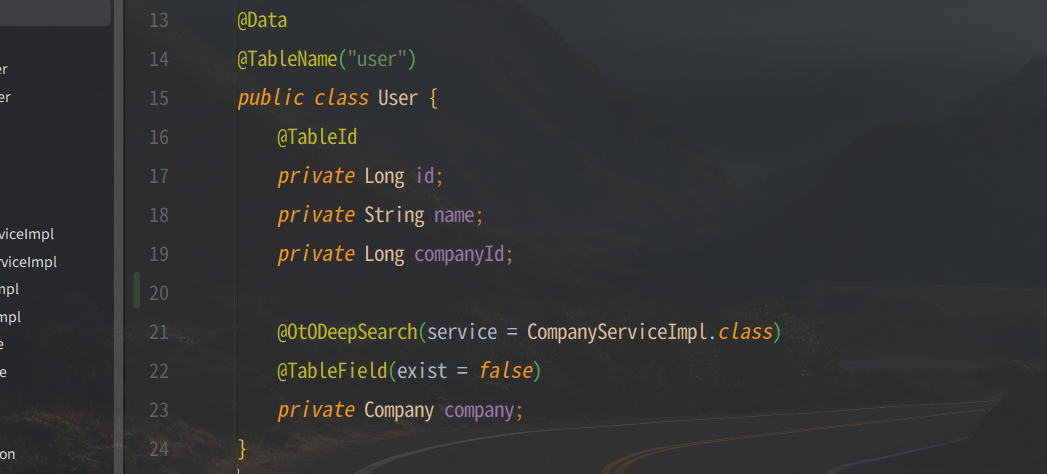
- 使用OtODeepSearch注解,指定查询服务
- baseId:基础id (
类字段名) 在该对象中用于查找目标对象的id信息,默认为注解字段+Id - service:查询服务,用于根据id查找目标对象
- notNull:非空检查,如果为true则在未查询到数据时抛出异常
一对多查询

- 使用OtMDeepSearch注解来完成一对多查询
- field:自身id的
类字段名,默认为id - baseId:目标表中对应自身id的
表字段名 - service:查询服务,用于查找指定对象列表
- notNull:非空检查,如果为true则在未查询到数据时抛出异常
多对多查询

- 使用MtMDeepSearch注解来完成多对多查询
- 多对多查询涉及三张表,相对复杂
- baseId:基础id (
表字段名)关联表中表示自己id的字段名 - targetId:目标id(
类字段名)关联对象中表示目标id的字段名 - relaService: 关联服务,用来查询关联信息
- targetService:目标服务,用来查询目标对象列表
- notNull:非空检查,如果为true则在未查询到数据时抛出异常
测试
让我们来构建一个复杂查询,包含一对一,一对多,多对多三种查询方式
查询测试:
测试结果:

demo下载地址:https://raw.githubusercontent.com/pqcqaq/imageSource/main/static/test-demo.7z